
Researchers from FAIR Reality Labs and the University of Southern Carolina have developed a method that reconstructs 3D clothed humans from a single monocular video.
The method, named ARCH (Animatable Reconstruction of Clothed Humans) is in fact a learned pose-aware model that produces detailed 3D animation-ready avatars using RGB image as input. The architecture of the model consists of three components: estimation of semantic space and a semantic deformation field, implicit surface reconstruction and finally colors and normals refinement component. Researchers designed the method in a way that the input is first transformed to a canonical space and then reconstructed and refined. This allows reducing geometry ambiguities caused by pose variations.
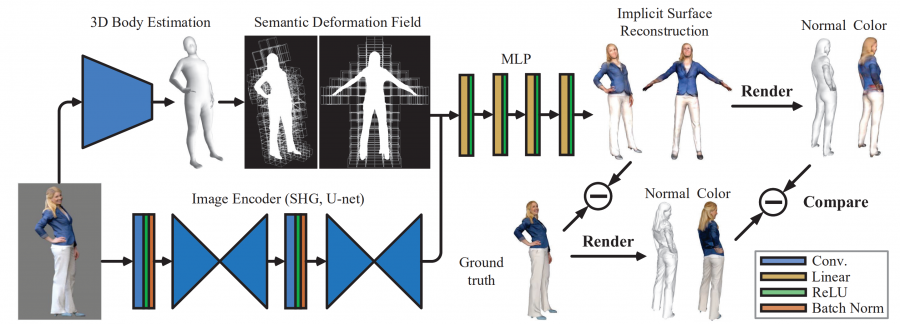
For training the proposed model, researchers used two datasets: RenderPeople and AXYZ dataset, which provide noise-free watertight meshes. The content of the scans in the datasets is people wearing different types of clothes and holding small objects. The method was evaluated both quantitatively and qualitatively on these datasets and the results show that it is superior to existing methods using reconstruction accuracy as an evaluation metric.
The method provides animation-ready models as output that can be driven by arbitrary motion sequences. Researchers open-sourced the implementation of the method, together with a demo Colab notebook. The paper was published on arxiv.


