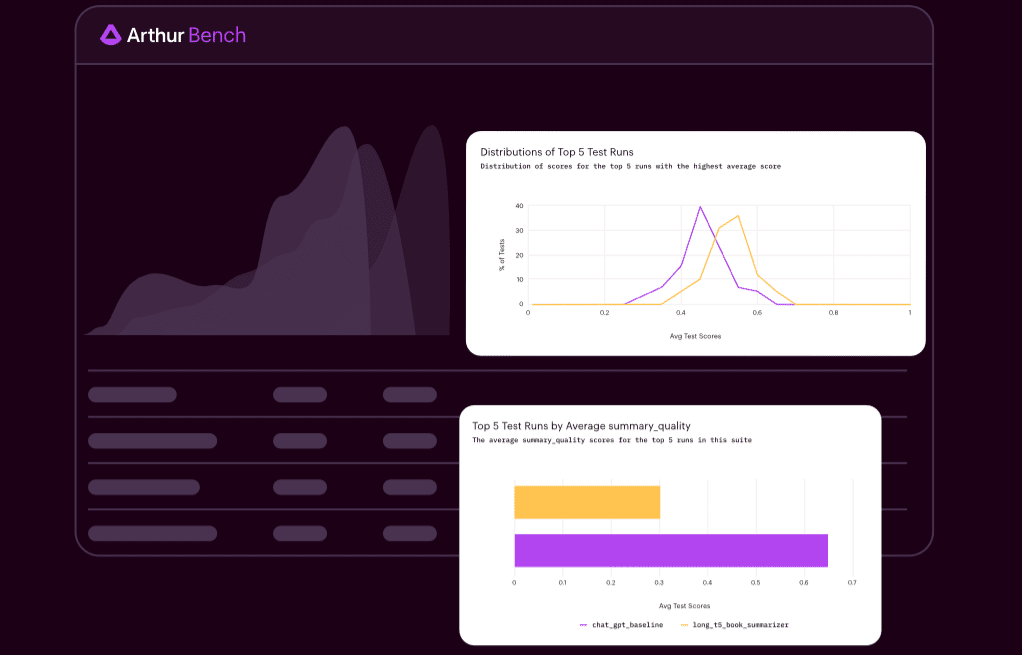
American startup Arthur has released an open-source framework called Bench for evaluating and comparing the performance of large language models. This tool enables users to select the most suitable language model for a specific task, provides effective guidelines for crafting queries, and determines the optimal training approach.
Arthur Bench offers metrics for comparing models based on answer accuracy, readability, hedging, and other criteria. Hedging is particularly relevant when utilizing language models in applications; models often include sentences in their responses that indicate limitations on their usage (“as a language model, I cannot…”), which is generally undesirable.
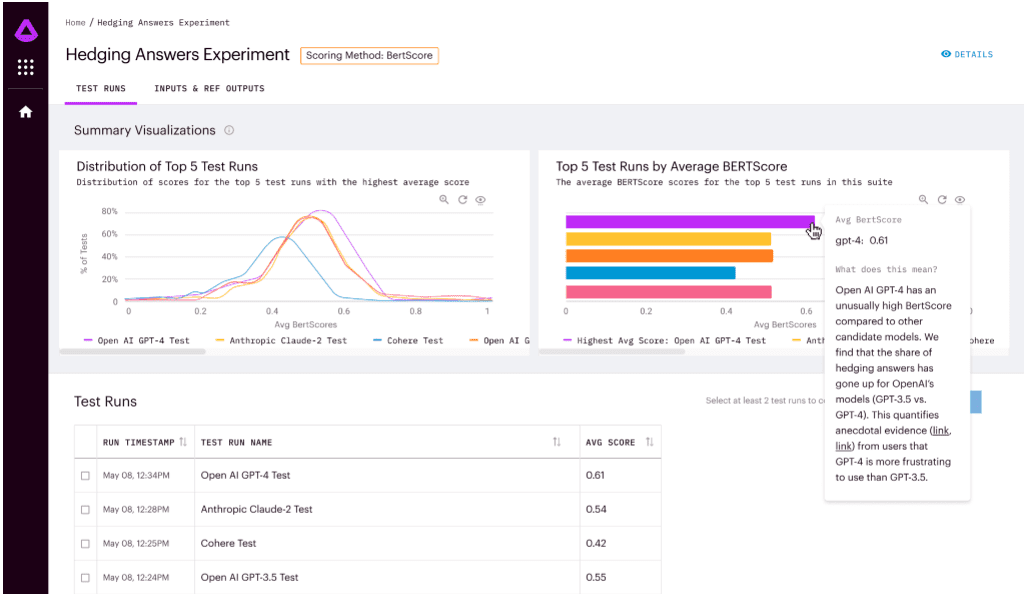
Bench simplifies the manual analysis of models. For instance, one can take 100 queries relevant to a specific task, and the tool will automatically compare responses from different models and highlight answers that significantly deviate from each other.
Since the framework has open-source code, users have the flexibility to add their own metrics according to their needs. Bench is already being utilized by several banks to consolidate investment analysis outcomes. Arthur has also announced a hackathon in collaboration with Amazon Web Services and Cohere, aiming to encourage developers to create new metrics for Bench.









