Researchers have open-sourced the implementation of the state-of-the-art voice model that can separate up to five different voices in a simultaneous conversation.
In July this year, FAIR researchers have published a paper describing their powerful method for voice separation. Considering that previous work in the area of voice separation was limited to a maximum of two speakers, the method greatly outperformed all existing methods, being able to separate up to five voices with great quality.
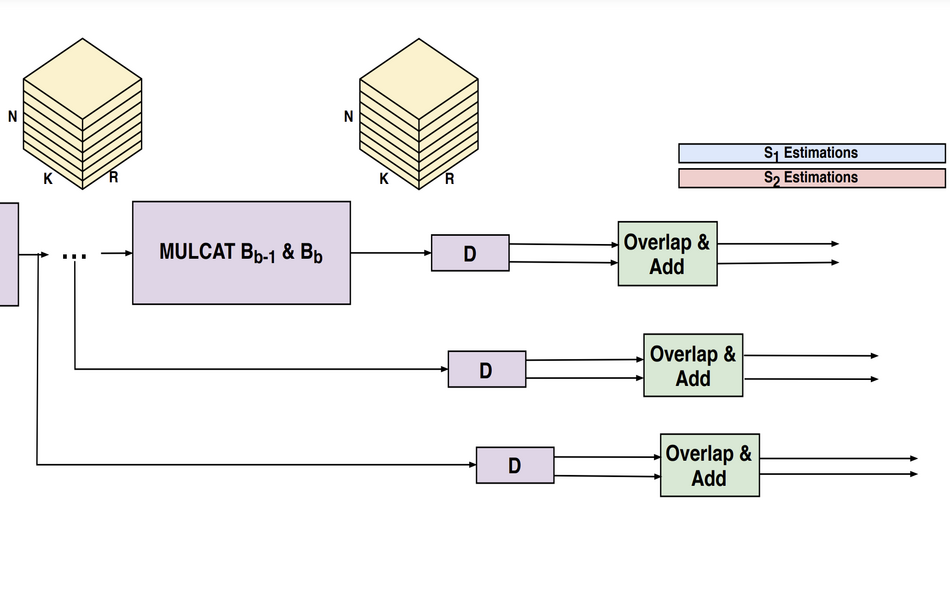
The idea behind the method is to train a different model for every number of possible speakers and select the most appropriate model for this ensemble. The model is in fact a gated convolutional neural network that takes as input a mixture waveform. This waveform is being convolved in the encoding stage using 1D convolutions and it is split into chunks of some length in time. Each pair of chunks are passed to a recurrent neural network (RNN) which is of type multiply-and-add. The final result of the voice separation is obtained after applying another convolution to the result from the previous stage and reordering the chunks.
Researchers used two public datasets to train and evaluate the proposed method: WSJ0-2mix and WSJ0-3mix. They also extended the WSJ-mix dataset to add four and five speakers introducing the new WSJ0-4mix and WSJ0-5mix datasets. Results showed that the method outperforms all methods on all the datasets with 2, 3, 4, and 5 speakers.