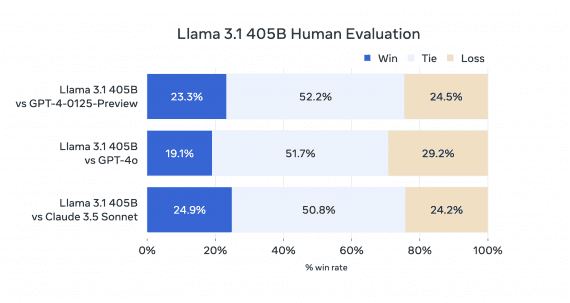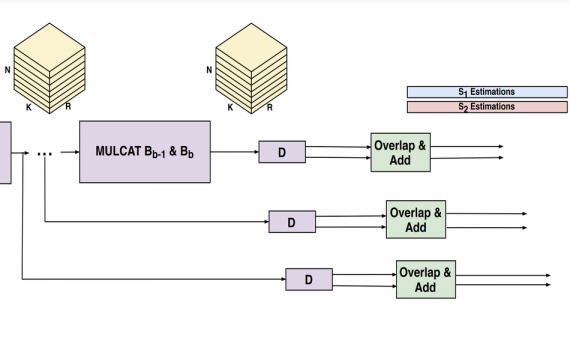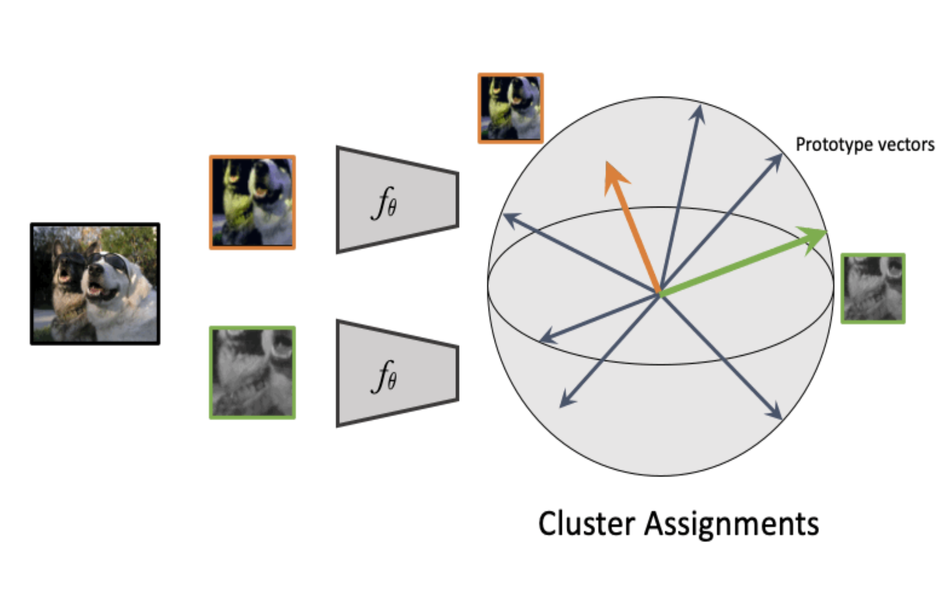
Researchers from Facebook AI Research have proposed a new self-supervised method for image classification that allows reaching the same accuracy as state-of-the-art models in much fewer iterations.
In their recent work, researchers explored one branch in self-supervised learning called contrastive learning. Self-supervised methods that rely on the paradigm of contrastive learning have proven to be serious alternatives to supervised learning, where labeled data is not available. However, due to the nature of these algorithms, obtaining high performance requires very long training meaning that these methods are in general very computationally inefficient.
In order to overcome this limitation, in the novel paper, researchers propose a method with several improvements. The method computes features of cropped regions of a pair of images and assigns each to a specific cluster. These two cluster assignments are constrained to match over time, by enforcing consistency between assignments for different augmentations. In contrast to other methods that rely on contrastive learning, pairwise comparisons are avoided and features are not compared directly in the new method. This can be seen from the scheme shown in the image below.
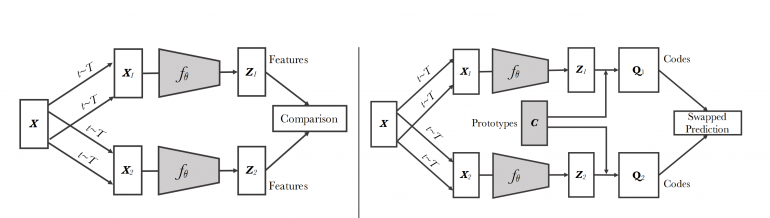
Researchers claim that their proposed method is way more memory and processing efficient than existing self-supervised methods that rely on contrastive learning. Together with the new method, researchers also proposed a novel data augmentation method called multi-crop.
More details about the method can be found in the arxiv paper. The implementation was open-sourced and can be found on Github.