Researchers from Imperial College London and the Samsung AI Centre have proposed a method for visual speech recognition that can perform lipreading and synthesize audio out from the signal.
To overcome the problem of speech recognition in noisy environments, the group of researchers designed a Generative Adversarial Network that is capable of the extracing raw audio signal from a person speaking videos. The researchers mention, that this is the first method that maps video directly to audio speech and the first method that can synthesize speech from previously unseen speakers.
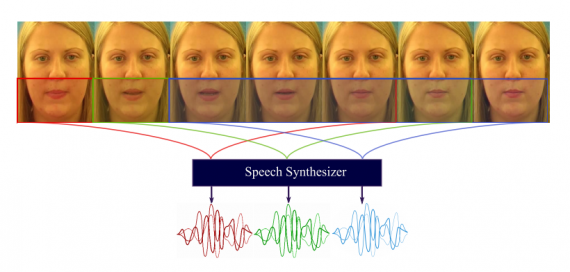
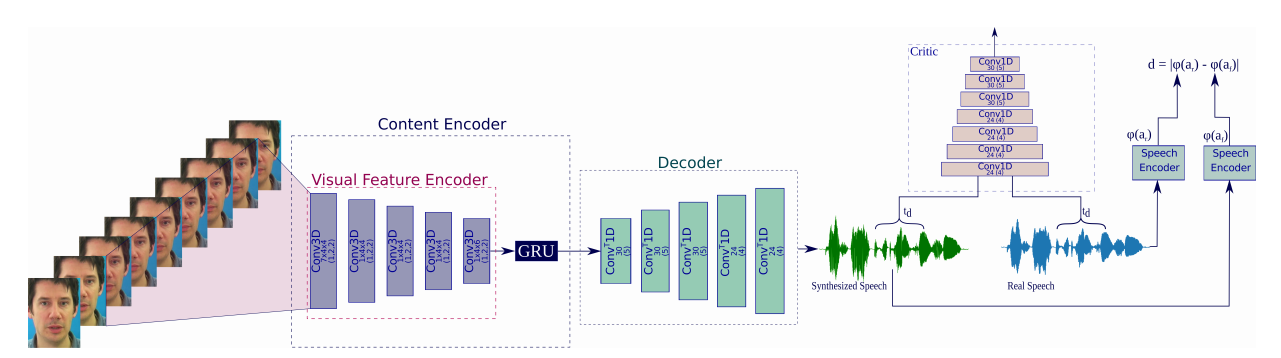
The proposed method consists of two parts: a visual feature encoder, and a decoder which synthesizes audio as it’s output. Researchers trained their model in the framework of Generative Adversarial Networks, by developing a “critic” module which should learn to distinguish between fake and real distribution of human speech and act as a discriminator.
The encoder module is a 5-layer, 3D CNN which encodes visual information from a window of consecutive frames in a video. A Gated Recurrent Unit is encoding temporal information and the decoder module is responsible to decode visual temporal information and generate speech. The discriminator learns how to distinguish distributions and forces the generator to decode the visual information in such a way that it resembles the characteristics of human speech.
The method was trained on the GRID dataset, that features 33 speakers with 1000 short phrases. Researchers mention that the method is capable of producing naturalistic sounding and they used several evaluation metrics to prove that. The model can synthesize speech for 3second videos in around 60ms when running inference on a GPU.
More details about the method and the evaluation can be found in the paper published on arxiv.



[…] ข่าวจาก vice.com/en/article/bvzvdw/tech-companies-are-training-ai-to-read-your-lips ภาพประกอบจาก neurohive.io/en/news/gan-network-can-do-lip-reading-and-output-speech […]