Google has introduced the RecurrentGemma language model, designed to operate locally on devices with limited resources such as smartphones, personal computers, and smart speakers.
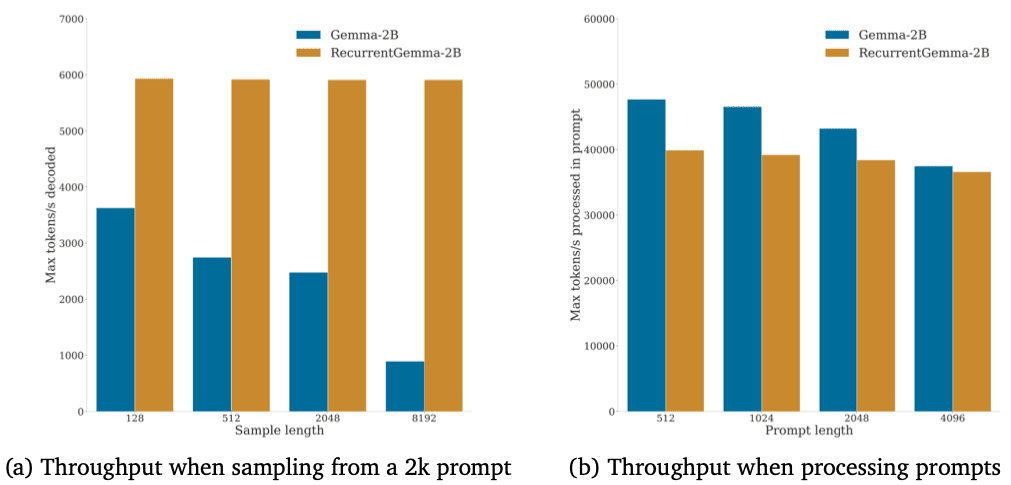
The new architecture from Google significantly reduces memory and processor requirements while maintaining excellent performance comparable to larger language models. This enables the use of RecurrentGemma in real-time responsive applications such as interactive AI systems and real-time translation services.
Modern language models, such as OpenAI’s GPT-4, Anthropic’s Claude, and Google’s Gemini, are based on the transformer architecture, which assumes an increase in memory and computational demands with the volume of input data processed. RecurrentGemma focuses on small segments of input data at any given time and does not consider all information in parallel, allowing it to process long textual sequences without the need to store and analyze large volumes of intermediate data.
The model is based on linear recurrent units, a key component of traditional recurrent neural networks. They operate by maintaining a hidden state that is updated as each new data unit is processed, effectively “remembering” previous information in the sequence.
The pretrained model contains two billion parameters and is available open-source.










