
Researchers from Google Research have proposed a novel approach to semi-supervised learning that achieves state-of-the-art results in many datasets and with different labeled data amounts.
In semi-supervised learning, methods use unlabeled data in combination with labeled data (usually in smaller amounts) in order to tackle a specific problem. Semi-supervised methods have proven to be successful in the past and bring an additional improvement over using only labeled data.
In their new paper named “MixMatch: A Holistic Approach to Semi-supervised Learning”, researchers introduce a new algorithm called MixMatch that is augmenting unlabeled data samples and is guessing low-entropy labels for those samples. The algorithm then combines labeled and unlabeled data to be able to learn from larger amounts of data.
The proposed MixMatch method is combining several dominant ideas from semi-supervised learning. It works by taking a batch of labeled samples alongside with a same-sized batch of unlabeled samples. The algorithm produces a batch of augmented labeled samples and a batch of augmented unlabeled samples with “guessed” labels. Those two batches are used to compute two different loss terms and finally a combined loss.
The labels for the unlabeled data samples are “guessed” or produced by the label guessing algorithm which researchers introduced. In fact, each unlabeled sample is augmented K number of times and each augmented sample is fed into a classifier. Predictions of different classifiers are then averaged and the distribution of guessed labels is sharpened before providing a final label.
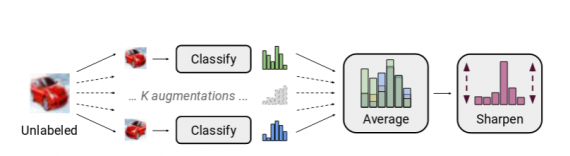
Researchers showed that the novel semi-supervised approach achieves good results in many datasets. The proposed approach achieves state-of-the-art results on CIFAR-10 with 250 labels reducing the error rate by a factor of 4 (from 38% to 11%) and also on STL-10 by a
factor of 2. In the paper, researchers also showed how the proposed algorithm can be used to achieve better accuracy-privacy trade-off for differential privacy.
The implementation of the proposed MixMatch method was open-sourced and it is available on Github. The paper can be read here.


