
Researchers from Uber have developed a new neural network that learns to generate it’s own synthetic data and uses it to learn the task rapidly.
Previous research has shown that neural networks are able to learn also from synthetic data and still generalize well. However, generating synthetic data is also a time-consuming process that relies on engineering environments that will provide such data.
In order to answer the question of whether it is possible to develop a learning algorithm that will generate data on it’s own, researchers from Uber designed a neural network architecture that learns to perform a task by training a generator and a learner.
They propose a two-loop learning algorithm where both a generator and a learner network are optimized jointly. In the first loop, the generator generates data that is used to train the learner network. Then, in the second loop, real data is used in order to compute meta loss which is actually used to update the generator’s weights. In this way, the network learns to generate data and to perform a task at the same time.
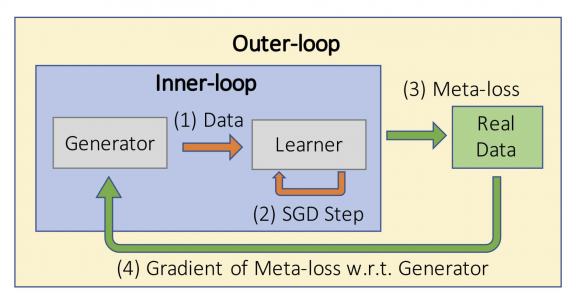
Researchers tested their approach on the popular MNIST dataset and they found out that the architecture is able to learn from its self-generated synthetic data at an even faster pace. Also, in their paper, they describe an interesting finding that most of the generated samples from the generator are unrecognizable (do not resemble real data) and “alien-like”.
More about the new method can be read in the official blog post. The implementation of the method will be open-sourced and will be available soon.


