
In a joint work, researchers from several universities have developed a novel method for unsupervised video object segmentation that significantly outperforms other existing methods at this task.
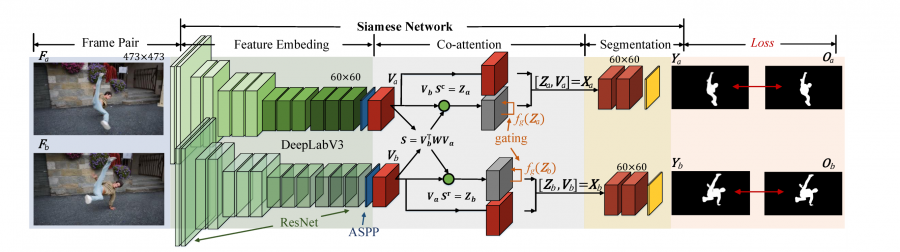
The new deep neural network model was named COSNet, short from CO-attention Siamese Network and is leveraging the power of the attention mechanism to capture correlations and provide unsupervised semantic segmentation. The network architecture was designed in a way that it accepts a pair of video frames. These frames are propagated through two encoder networks to obtain embedded feature representations for both the images. Then, a co-attention module captures the correlation between these representations and the result is given to a final segmentation module. The last module performs pixel-wise semantic segmentation using the standard weighted (binary) cross-entropy loss.
Researchers used three large benchmarks to evaluate the performance of their proposed method: DAVIS16, FBMS, and Youtube Objects. The results showed that the method achieves superior results on the three video segmentation benchmarks, outperforming current state-of-the-art methods.
In their paper, researchers mention that the method can easily be extended to other video analysis tasks and can be seen as a general framework for handling sequential data learning. Within their proposed framework, they explored different co-attention variants for mining rich context in videos that can be used to tackle other tasks.
The implementation of the method was open-sourced along with some pre-trained models and can be found on Github. More in detail about the COSNet method can be read in the pre-print paper published on arxiv.