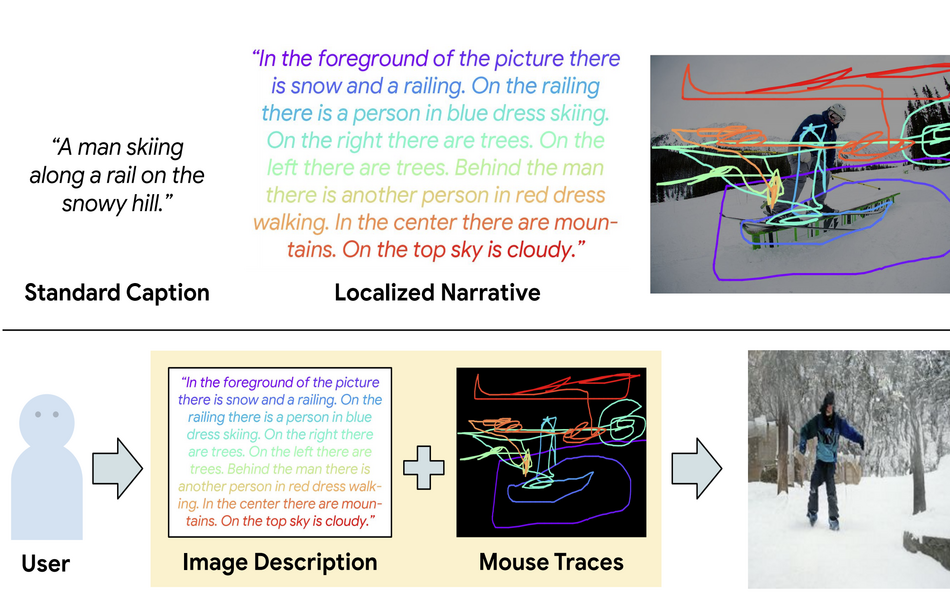
A group of researchers from Google Research has proposed a novel method for text-to-image generation that outperforms existing direct text-to-image generation models.
In their work, researchers designed a sequential neural network model that works on top of the specific Lozalized Narratives dataset. In this multi-modal dataset, every image in the set is accompanied by a phrase but also a mouse trace that loosely corresponds to the text i.e. description of that image. Using this dataset, researchers were able to predict specific objects appearing in parts of the image given by the mouse trace. This provides a base for easier object detection I.e.localization within the image frame and therefore easier coupling with the description.
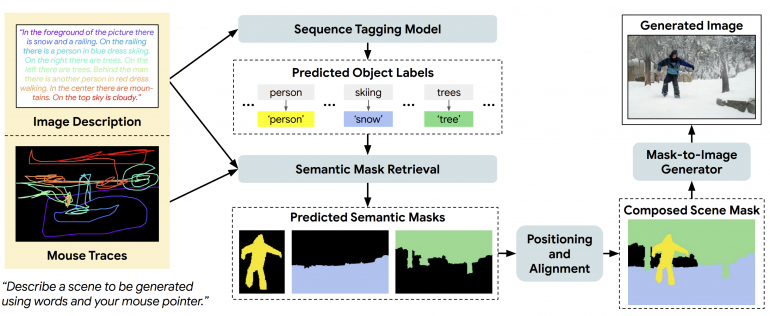
The proposed model, called TReCS, uses the data in order to estimate predicted semantic masks for each object which after alignment are converted to images of objects and finally fused into the resulting image. The model consists of several stages. The first stage is the Sequence Tagging, where a dedicated model extracts entities from the input description and predicts object labels. The mouse traces along with the description are provided together to the second stage – the Semantic Mask Retrieval stage which tries to predict one segmentation mask per each object from the previous stage. In the final stage, the semantic segmentation masks are re-aligned spatially and a Mask-to-Image generator model is used to synthesize the final output.
Researchers used a variant of the popular COCO dataset, named LC-COCO (stands for localized narratives COCO) to evaluate the performance of the proposed method. They performed a quantitative evaluation as well as a qualitative one with the focus being on the perceived image quality. They designed a few experiments and asked participants to grade the synthesized images. Results showed that TReCS achieved superior results from these surveys outperforming existing methods by a large margin. They also reported that the method outperforms baseline methods in terms of quantitative metrics such as FID (Frechet Inception Distance) and Inception Score (IS).
More about the architecture of the model as well as the experiments conducted can be read in the paper published on arxiv.


