Researchers from Facebook AI have open-sourced a method and a system that can predict if a Covid patient will need intensive care, using chest x-ray images and self-supervised learning.
In their paper, researchers argue that the lack of data on Covid patients makes it difficult to produce useful models trained with supervised-learning methods. In order to overcome this issue, they designed a self-supervised method for detecting a so-called Covid deterioration – need for intensive care, need for large amount of oxygen or mortality.
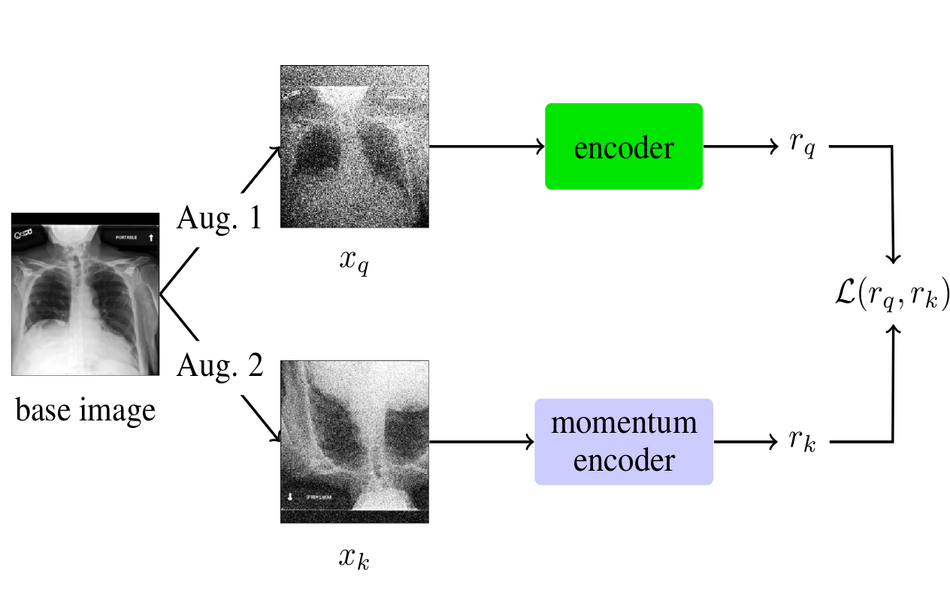
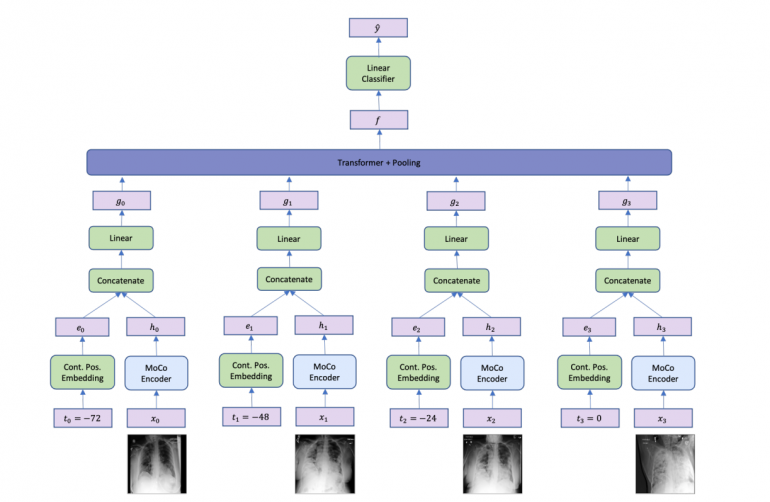
The proposed method is based on the momentum-contrast (MoCo) method for self-supervised representation learning. In fact, two different methods were proposed: SIP, or Single Image Prediction model and MIP or Multiple Image Prediction model. For the single-image model, researchers used a MoCo framework which was modified to a classifier setting by adding an additional linear classifier in the end, after the encoder. The MIP model, takes a sequence of x-ray scans at different times as an input, as opposed to the single image input in SIP. Each of the images goes through a MoCo encoder and the latent representation is concatenated with a time embedding. The resulting representation is then fed to a Transformer network to aggregate the information. In the end, similarly as in the SIP model, a linear classifier is added to provide a classification prediction.
Researchers used two public datasets for pre-training of the models: MIMIC-CXR and CheXpert. For the fine-tuning part they used the NYU Covid Dataset that contains more than 26 000 x-ray scans. The models were trained as binary classifiers using only two classes: 1) adverse events (that includes hospitalization, intensive care, intubation or mortality) and 2) increased oxygen requirements.
Results from the experiments showed that the models achieve 0.742 AUC score for predicting an adverse event up to 96 hours in advance. This score drops to only 0.691 for a time frame of within 24 hours. The multi-image model achieved superior results compared to the single-image (SIP) model.
The implementation of the Covid prognosis method was open-sourced and can be found on Github. The paper was published in arxiv.


