
Researchers from Google Brain have proposed a new representation learning method for Scalable Vector Graphics (SVGs). They showed how the learned representations can be used to extract high-level characteristics of objects in vector images and they used this to generate SVG fonts.
Arguing that understanding of imagery does not arise from exhaustively modeling an object,
but instead identifying higher-level attributes that best summarize a certain object, researchers attempted to build sequential generative models of vector graphics.
In the context of representation learning, the goal of the authors is to learn a drawing model from a large set of example images. The main objective is that the model captures the underlying structure in the images and is able to generate drawings based on the learned representation. However, the expected representation is not a pixel representation of an image but rather a sequence of rendering instructions for a graphics engine.
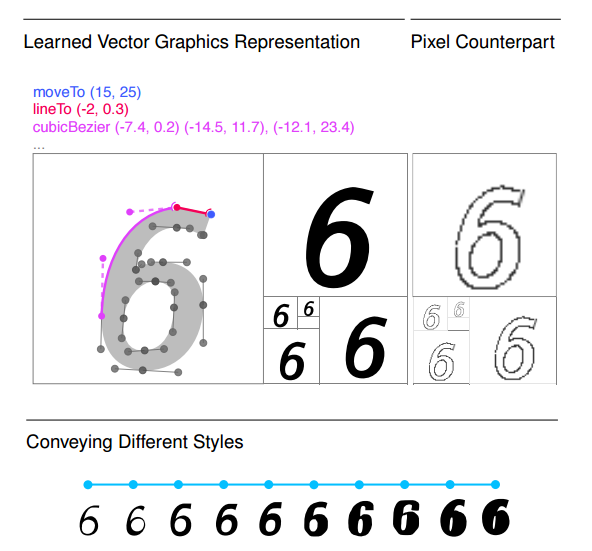
To be more precise, the focus of the researchers was on Scalable Vector Graphics as a well-known and widely used format for fonts and drawings.
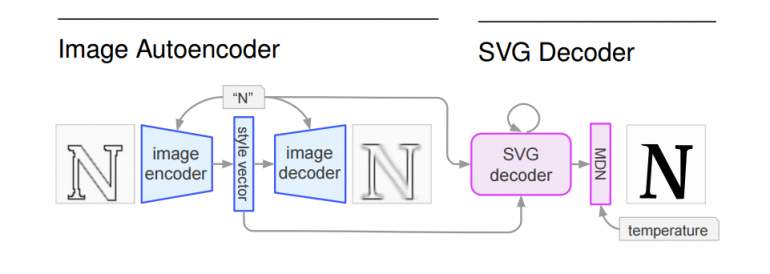
The proposed solution was a generative neural network model with a two-stage architecture: an autoencoder – used to learn an SVG representation from images in SVG format and an SVG decoder – that takes a latent vector representation from the autoencoder and decodes it to SVG representation of rendering instructions.
The autoencoder that was employed is a Variational Autoencoder (VAE), whereas the SVG decoder consists of several LSTMs and a Mixture Density Network (MDN).
Researchers used a font dataset of 14M examples of 62 characters (as SVG fonts). They demonstrated that the generative model is able to learn a perceptually smooth latent representation, that supposedly captures a large amount of variation within the dataset.
They showed that the model is able to infer a complete SVG font set out of a single character of a font. Also, they provide samples of generated images by sampling a random latent representation and running the SVG decoder conditioning on z and all class labels.
More details about the method and the evaluation can be in the pre-print paper published on arxiv.


