Google AI has announced the release of a new version of the popular Open Images dataset – Open Images V6. The new version comes with an expanded set of annotations for the 9 million images already present in the dataset which include localized narratives as well as visual relationships, human action annotations and image-level labels.
Researchers in the field of Computer Vision have tried to tackle the problem of describing a scene or an image in a large number of ways. Understanding the action and the actors involved in an image has been a challenging problem for a long time. Driven by this goal, researchers built datasets which try to provide descriptions and visual relationships between objects in an image. In this context, the new version of Open Images now includes new visual relationships (for example “dog catching a flying disc”) for 1.4 thousand images with provided bounding boxes for the objects and the action. Additionally Open Images V6 features 2.5 million annotations of human actions and an increased number of human-verified image-level labels (23.5 million new annotations). With this, the Open Images dataset reaches almost 60 million images with over 20K categories.
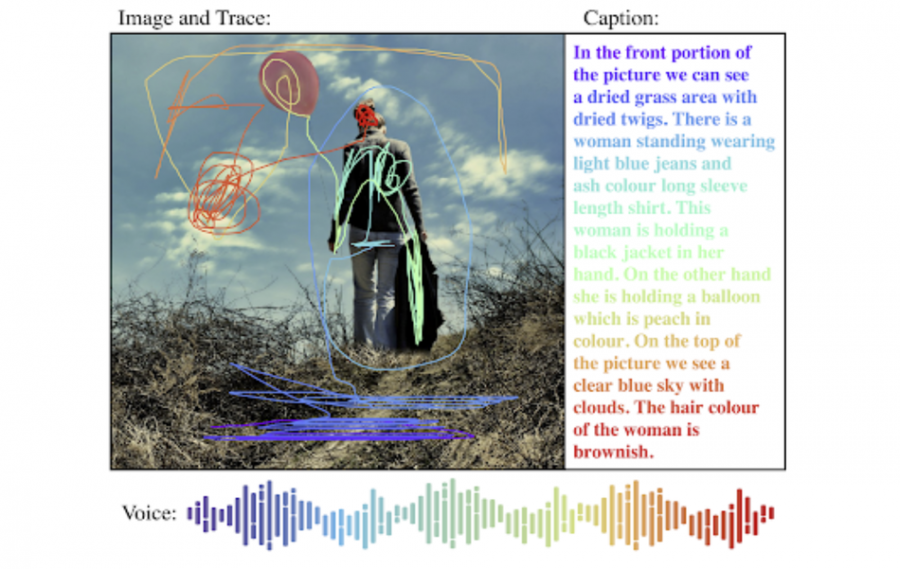
However, the biggest feature of Open Images V6 is not the increased number of annotations, but a completely new type of annotation called: localized narratives. This is a new form of multi-modal annotation that combines synchronized text, voice and mouse traces over objects in an image. Researchers included 500K images with localized narratives. According to researchers, the voice annotation is the core of this approach since it connects the description of an image to the regions of the image that are being referenced. In their blog post, they mention that localized narratives as a novel annotation type can help in studying how people describe images.
The latest version of Open Images can be downloaded from here. More details about the new annotations can be read in the official blog post.


