In a recent paper, a group of researchers from Oxford, Cambridge, UC Berkeley and UCL has proposed a new pre-training method for point cloud models that relies on point cloud completion as an intermediate task.
Very often, point clouds coming from real-world static sensors are sparse in the sense of capturing information only from a specific, pre-determined viewpoint. The occluded portion of the scene is completely missing in these point clouds, making further processing and information extraction on these point clouds a challenging task.
Point clouds are an important part of many real-world robotics applications including autonomous driving. Tasks such as object detection, 3D object detection, segmentation, etc., often suffer due to the lack of information present in the sensor data. In order to tackle this problem, researchers proposed a novel method where they pre-train a model using a point cloud completion model.
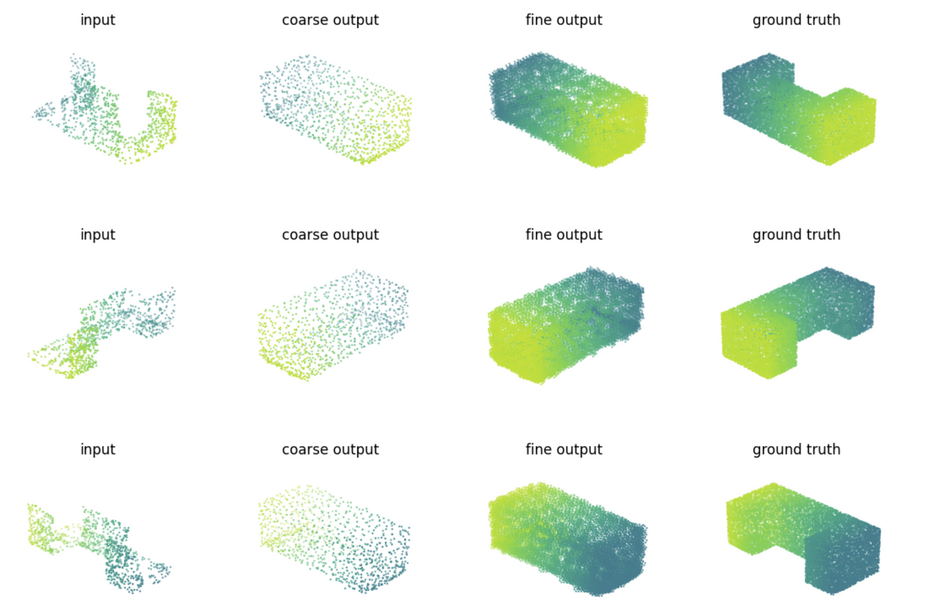
In their proposed approach, they take full (completed) point clouds and generate partial point clouds (occluded ones) by changing the viewpoint and estimating an object surface in the camera frame perspective. Using those mappings (of original and sparse point clouds) they train an encoder-decoder model in a self-supervised manner to learn point cloud completion tasks.
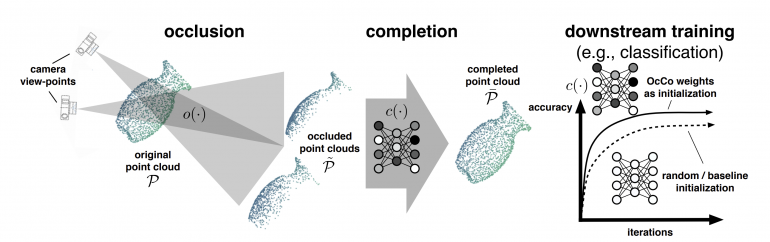
In the end, the encoder weights from the trained model are used as initialization weights for any downstream point cloud task such as the ones we mentioned before: object detection, segmentation, registration, etc.
Researchers showed that their approach, nicknamed OcCo is able to capture visual constraints and help downstream models better converge to optimal solutions. The experiments confirmed that the approach is transferable across different point cloud datasets and that it can reduce training i.e. convergence time.
The implementation of the pre-training method was open-sourced and can be found on Github.