A group of researchers from the American Library of Congress has joined forces to create a large-scale dataset from newspaper content by analyzing over 16 million historic newspaper pages.
As part of an initiative of the National Digital Newspaper Program of America, the so-called “Newspaper Navigator” project had the goal of creating a semantified corpus out of the large set of digitalized historic newspapers from America. This set of legacy newspapers’ content was part of Chronicle America and it contains high-resolution visual content (or images) as well as machine-readable text. Researchers from the Library of Congress had the idea to employ deep learning in order to extract valuable and structured information from this set in an automatic way.
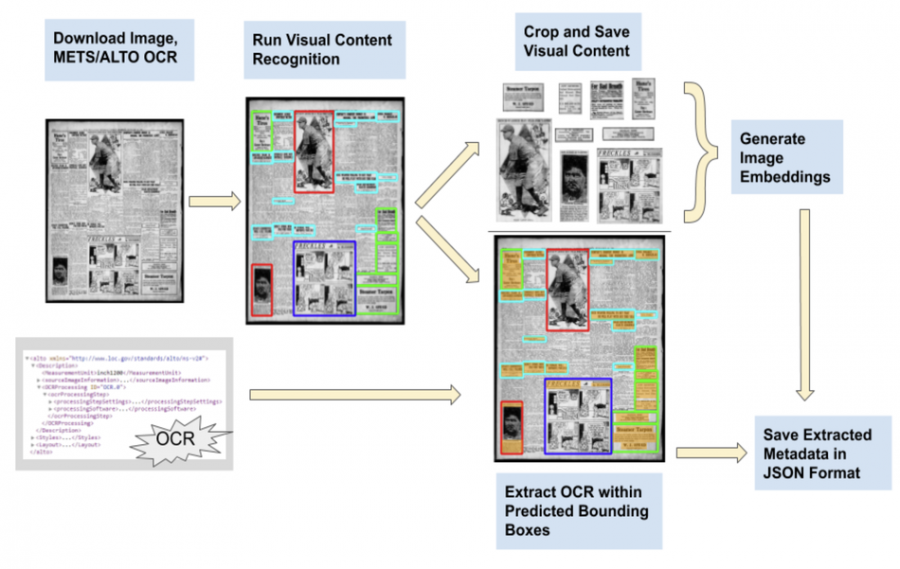
To achieve this goal, researchers designed a processing pipeline that leverages the advances in deep learning for both visual and textual data. The proposed pipeline extracts several classes of visual content (headlines, photos, maps, comics, etc.) along with textual content such as image captions. Additionally, the pipeline provides image embeddings for fast visual content retrieval from the large dataset.
The pipeline was used to extract information from the 16.3 million newspaper pages from the Chronicle America corpus and to create a novel large-scale dataset called Newspaper Navigator dataset.
Researchers open-sourced the new dataset, together with all the source code used to generate it for unrestricted re-use, as they mention in the paper. The dataset can be found on the following link. More details on how the dataset was curated and a description of the proposed processing pipeline can be found in the paper.


