
Researchers from Google Brain have proposed a novel pre-training technique called Selfie, which applies the concept of masked language modeling to images.
Arguing that language model pre-training and language modeling, in general, have been revolutionized by BERT – the concept of bi-directional embeddings in masked language modeling, researchers generalized this concept to learn image embeddings.
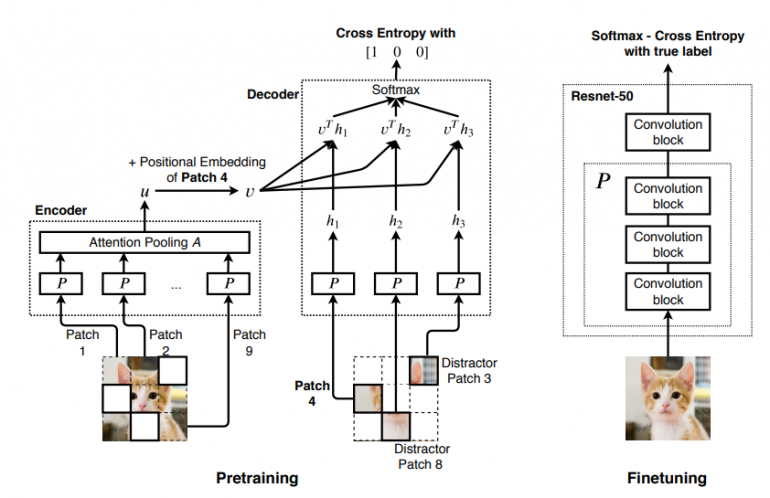
In their proposed method they introduce a self-supervised pre-training approach for generating image embeddings. The method works by masking out patches in an image and trying to learn the correct patch to fill the empty location among other distractor patches from the same image.
The method then uses a convolutional neural network to extract features from (unmasked) patches, which an attention module is trying to summarize before predicting the masked patches.
Researchers showed that this kind of embeddings drastically improves classification accuracy. They conduct a number of experiments trying to evaluate how the proposed embeddings method affects the performance of different models and with different amounts of labeled data.
They showed that Selfie provides consistent improvements in all datasets compared to training in a standard supervised setting. CIFAR-10, ImageNet 32 and Imagenet 224 were the datasets used, and researchers designed specific experiments varying the portion of labeled data (from 5% all the way to 100%).
Additionally, researchers observed that the proposed pre-training method improves the training stability of ResNet-50.
This method shows how an idea that was a breakthrough in Natural Language Processing can also be applied in Computer Vision and improve the performance of models significantly. More about Selfie can be read in the pre-print paper published on arxiv.


