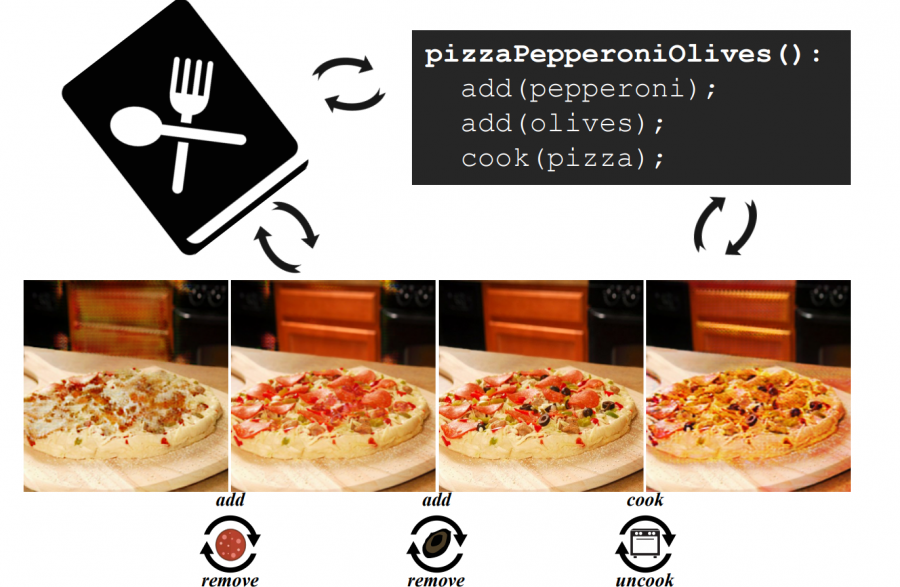
In a novel paper, researchers from the Massachusetts Institute of Technology and the Qatar Computing Research Institute show how learning a compositional GAN model can be used to visually construct a pizza image.
Researchers mention that a food recipe is represented as a sequence of instructions and therefore every instruction step in the process can be seen as changing the visual appearance of the dish. They proposed a step-by-step method based on compositional Generative Adversarial Networks that can make a pizza by adding ingredients and compiling an image.
The proposed method is based on learning composable modules which are able to add or remove a particular ingredient from the dish (the visual appearance in the image). Each of these modules is in fact, a designed and trained GAN model.
The designed architecture allows the model to decompose an image by removing ingredients one-by-one. For each of these ingredients, researchers build a specific module (a neural network) which takes as input an image and outputs the same content in the pizza with an extra ingredient added or removed.
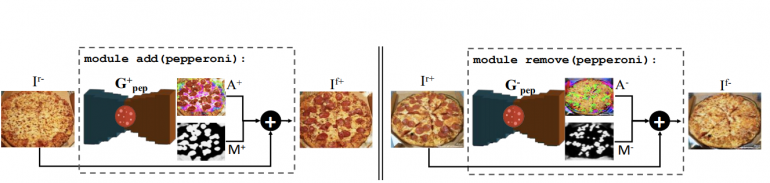
Researchers tackle the problem from the perspective of multi-label classification where they split the training images according to the presence of a particular ingredient – the appearance of a particular class.
For the purpose of training their models, researchers thought of using the hashtag pizza, which is the most photographed food. They collected half a million images and crowd-sourced the labeling efforts.
The evaluations of the method showed that it learned to segment pizza toppings, it learned to perform image inpainting (when removing ingredients) and it is able to infer the ordering of pizza toppings without any supervision.
The implementation of the method was open sourced together with the data and the pre-trained models and can be found here.


