The Transformer architecture or Transformer models have been one of the largest breakthroughs in AI in the past decade. One of the most powerful models, namely GPT-3 is based on this architecture and is capable of doing many tasks very well. However, the Transformer architecture or attention did not disrupt computer vision models as it has done with NLP models, and it has been used in some form as part of convolutional networks (CNNs).
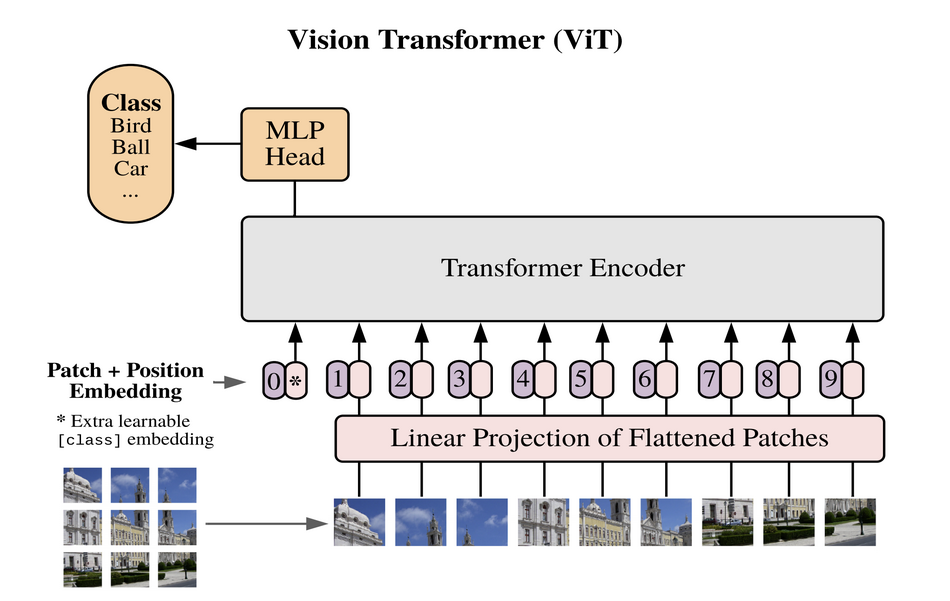
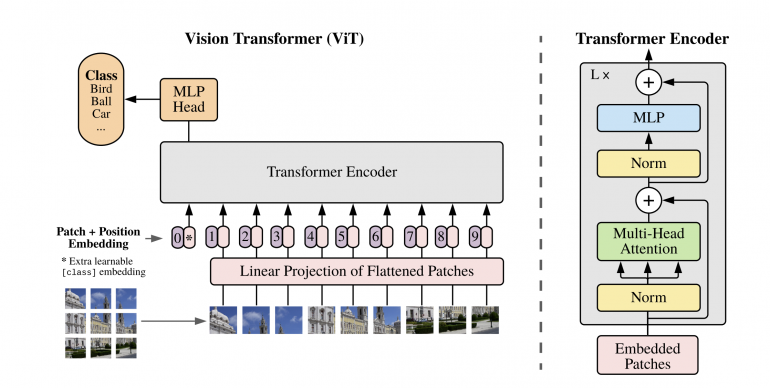
In order to prove that transformers can be powerful even when applied to image data, researchers from Google Brain have designed an architecture that directly applies Transformer architecture on a set of image patches considered as “words”. In their proposed method, they split an input image into fixed-size patches, and feed the linear projections of these patches along with their image position into a Transformer encoder network.
Additionally, the input to the transformer encoder consists of an extra learnable embedding for the class, similar to the “class” in BERT models. The output of the encoder is given to an MLP head with a single hidden layer that performs the final classification. A scheme of the proposed architecture is given in the image below.
Researchers conducted many experiments to evaluate the representation learning capabilities of the proposed framework. Also, in order to evaluate the scalability, they trained the models with large-scale datasets such as ImageNet 1.3M, ImageNet-21K with 14 million images, and JFT with 303 million images.
The results from the experiments showed that the proposed Vision Transformer (ViT) achieves very good results in classification even when compared to state-of-the-art CNNs, and it achieves that requiring less computational resources for training.
More information can be found in the paper published on arxiv.