Researchers from CUHK, NUS, University of Oxford, and Video Rebirth introduced Video Reality Test — the first benchmark that tests whether modern AI models can create videos indistinguishable from real ones. Unlike existing tests that verify physical plausibility, this benchmark directly answers the question: is this video real or generated? Results show that even the most advanced multimodal language models (VLMs) achieve only 76.27% accuracy on average, far below human performance of 89.11%. The project is partially open-source and available on the official website.

The benchmark is based on ASMR videos (Autonomous Sensory Meridian Response) because they require perfect audio-video synchronization. The slightest artifacts instantly break immersion, making ASMR an ideal testing ground for verifying realism.
How Video Reality Test Works
Researchers collected 1,400 popular ASMR videos from YouTube (over 900 thousand views) and selected 149 representative samples. High popularity serves as a quality indicator — if a video has many views, it successfully triggers a sensory response. Each video underwent processing: segmentation, background and watermark removal, first frame extraction, description generation via Gemini-2.5-Pro, and clustering via Qwen3-embedding-4B.

Videos are divided into two difficulty levels: easy (49 videos) — short 3-5 second clips with single-step actions on uniform backgrounds; hard (100 videos) — up to 20+ seconds with multi-step actions, diverse backgrounds, and materials (solid and liquid).
Unlike other benchmarks with fixed datasets, Video Reality Test uses a dynamic approach. Video generation models (VGMs) create their own fake samples, turning the benchmark into a continuous arena of size 149 × (1 + K), where K is the number of generative models.
Peer-Review: Models Competing Against Each Other
Researchers introduced the Peer-Review methodology. VGMs act as “creators” trying to fool “reviewers,” while VLMs act as “reviewers” identifying fakes. For reviewers, accuracy AccU is calculated; for creators, the FakenessG metric (percentage of detected fakes). The lower the FakenessG, the more realistic the generator. The higher the AccU, the better the detector.
VLM Results
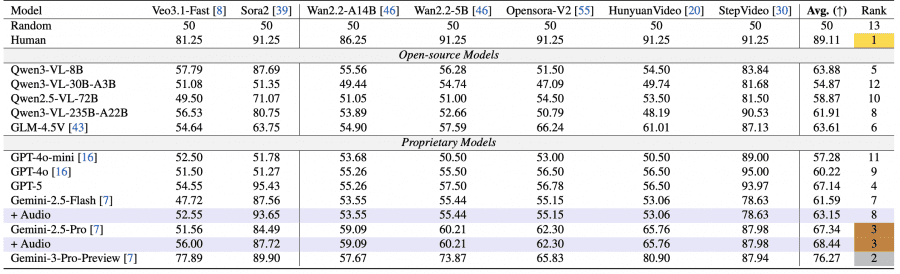
Eleven models were tested: proprietary Gemini-2.5-Pro/Flash, GPT-4o/4o-mini, GPT-5, and open-source Qwen and GLM. Gemini-3-Pro achieved 76.27%, Gemini-2.5-Pro — 67.34%. Humans successfully identified AI videos in 89.11% of cases. Most open-source models performed significantly worse — Qwen3-VL-30B-A3B only 54.87%, barely above random (50%).
The most interesting result: the best generator Veo3.1-Fast fooled even Gemini-2.5-Pro, which recognized only 56% of its videos (with random being 50%). This is 25% lower than human accuracy of 81.25%.
A systematic bias toward classifying as real was identified in VLMs. Gemini-2.5-Pro on 100 real and 100 fake videos from Wan2.2 classified 71% of all videos as real and only 29% as fake. Qwen2.5-VL-7B incorrectly identified all generated Wan videos as real.
VGM Results
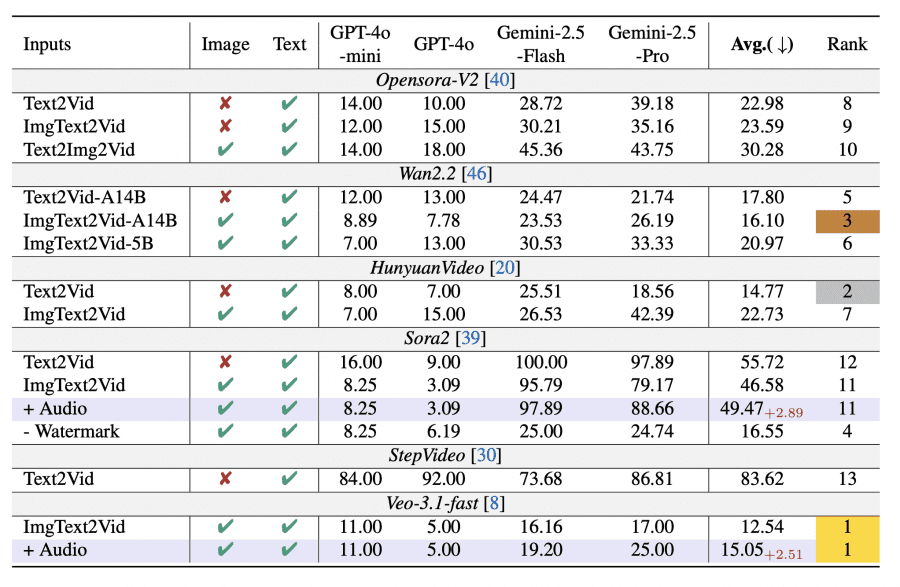
Eight generators were tested: Wan2.2, OpenSora-V2, HunyuanVideo, StepVideo, Sora2, Veo3.1-fast. The best was Veo3.1-Fast — only 12.54% of its videos were identified as fake. In second place were HunyuanVideo-I2V (14.77%) and Wan2.2-A14B (16.10%), showing the narrowing gap between proprietary and open-source models.
Sora2 without watermark (16.55%) performed 30 p.p. better than with it (46.58%). With watermark, Sora2 ranked 11-12th, after removal it rose to 4th. Model size matters: Wan2.2-A14B (14B parameters) outperformed Wan2.2-5B — 16.10% vs 20.97%.
The Role of Audio
Adding audio improved detection for top models. For Gemini-2.5-Flash, accuracy increased from 61.59% to 63.15% (+1.56 p.p.), for Gemini-2.5-Pro — from 67.34% to 68.44% (+1.1 p.p.). This is related to poor audio synchronization in generated videos. Sora2 generates human voices instead of continuous ASMR sounds, creating a mismatch. Veo3.1-Fast handles generating specific sounds without speech better, but adding audio still increased its detection probability from 12.54% to 15.05% (+2.51 p.p.).
The Watermark Problem
A critical VLM vulnerability was discovered — dependence on watermarks. On Sora2 videos with watermarks, top VLMs showed abnormally high accuracy: Gemini-2.5-Flash — 93.65%, GPT-5 — 95.43%, even the relatively weak Qwen3-VL-8B reached 87.69%. On other generators without watermarks, the same models showed around 55%.
After watermark removal, performance collapsed. GPT-4o barely changed (51.8% → 52.8%), but GPT-5 dropped from 95.4% to 53.4% (-42 p.p.), Gemini-2.5-Pro from 84.5% to 56.0% (-28.5 p.p.), Gemini-2.5-Flash from 87.6% to 52.6% (-35 p.p.). Analysis of the reasoning process showed that Gemini and GPT-5 explicitly mention the watermark in their reasoning and classify videos as fake based on it, ignoring visual quality. GPT-4o does not demonstrate this behavior. This means high accuracy is achieved through superficial shortcuts rather than understanding perceptual fidelity.
Typical Generator Errors
Analysis of failures revealed four main VGM error patterns: corrupted or empty files (17.6%), incomplete work — for example, 8-second videos instead of 8 minutes (35.7%), low quality — primitive graphics made of basic geometric shapes, robotic voice-over (45.6%), inconsistency between video parts — for example, 3D renders of the same building from different angles showing incompatible architectural details (14.8%).
Most failures are related to models’ lack of self-verification ability. This is especially noticeable in tasks requiring complex visual validation: architectural design, game development, web design. A generator can create a 3D model of a house or an interactive game but doesn’t understand when the result works incorrectly or looks unnatural.
At the same time, AI performed well on a small number of tasks. These are primarily creative tasks: audio editing (creating sound effects, separating vocals from music), generating advertising images and logos, writing reports, creating simple interactive dashboards with data visualization.
Comparison with Other Benchmarks
Unlike existing benchmarks for video generation (VBench, VideoPhy) and video understanding (SEED-Bench, MV-Bench), Video Reality Test is the first unified benchmark containing real and fake video pairs with audio, designed for simultaneous evaluation of both VLMs and VGMs. The benchmark uses multimodal input data (text, image, audio) and introduces a new Peer-Review evaluation paradigm where generators and detectors compete against each other.
Existing AIGC detection benchmarks (GenVideo, LOKI, IPV-Bench) evaluate only understanding models but not generation. Video Reality Test fills this gap by providing a dynamic arena where generator quality is measured by their ability to fool detectors, and detector quality by their ability to identify fakes.
Conclusions
The main finding of the study: despite impressive AI performance on academic knowledge and logic tests, models are still very far from truly understanding perceptual fidelity and creating content indistinguishable from reality. The best generator Veo3.1-Fast reduces the accuracy of the strongest reviewer Gemini-2.5-Pro to 56% (with random being 50%), which is 25% below human level.
Video Reality Test revealed three critical problems of modern VLMs: dependence on superficial features (watermarks) instead of quality analysis, systematic bias toward classifying videos as real, and limited ability to use audio-visual consistency for detection. The dataset is planned to be expanded with new projects, and code and examples are available on the official project website for anyone wanting to test their models.