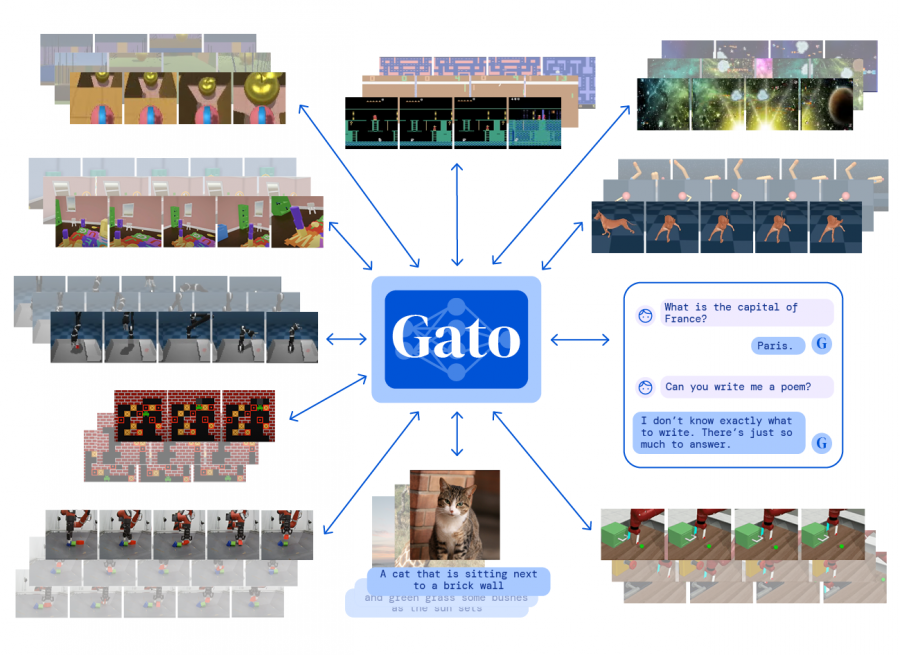
DeepMind has introduced a cross-modal universal model with 1.2 billion Gato parameters. Gato can perform more than 600 tasks, such as playing video games, creating subtitles for images and controlling robots.
DeepMind has trained Gato on datasets that include agent experience in both simulated and real environments, as well as on natural language and image datasets.
Gato has a transformer architecture that has been chosen to solve complex reasoning tasks, demonstrate the ability to generalize texts, create music, classify objects in photographs and analyze protein sequences.
At the Gato training stage, data from various tasks and modalities are ordered into a flat sequence of tokens, combined and processed by a neural network.
Interestingly, Gato has orders of magnitude fewer parameters than single-tasking systems, including GPT-3. So, GPT-3 has more than 170 billion parameters, while Gato has only 1.2 billion.


