
A team of researchers from Peking University and ByteDance published Helios — an autoregressive diffusion transformer with 14 billion parameters that generates video at 19.5 frames per second on a single NVIDIA H100 GPU. That’s 128× faster than the base Wan-2.1 model, and comparable in speed to several distilled 1.3B models. The model supports video generation of over a minute in length without quality degradation — something most existing solutions fail to achieve.
The project is fully open: the authors published the code on GitHub, along with a demo and weights for all three versions on HuggingFace:
- Helios-Base (14B) — the base version with maximum quality and 50 sampling steps;
- Helios-Mid (14B) — with aggressive token compression for ~2× speedup at a slight quality cost;
- Helios-Distilled (14B) — a distilled version with just 3 sampling steps and real-time speed of 19.5 FPS.
Native support in Diffusers, vLLM, and SGLang was released on the same day. The authors also released HeliosBench — a benchmark with 240 prompts covering four duration ranges from 81 to 1440 frames — for evaluating long video generation models.
Why does real-time video generation matter?
Most modern models — from Wan 2.1 to HunyuanVideo — are slow. Wan 2.1 14B takes around 50 minutes to generate a 5-second clip on an A100 GPU. That’s catastrophically slow for interactive applications — game engines, interactive worlds, real-time creative tools.
Real-world use requires models that generate video faster than it plays back.
Existing attempts to solve this — Self-Forcing, Rolling Forcing, Krea-RealTime — are either built on small models (1.3B parameters) that lack quality, or fail to handle error accumulation in long videos.

Three core problems Helios solves
Problem 1: error accumulation (drifting) in long videos. When an autoregressive model generates video in chunks — each new segment based on the previous one — errors accumulate over time. Colors start to drift, objects change shape, blurring artifacts appear. The authors identified three types of degradation: position shift, color shift, and restoration shift.

Problem 2: speed. Generating a 14B model quickly seemed impossible without KV-cache, quantization, or sparse attention. Helios manages without any of these techniques.
Problem 3: memory during training. Standard training of a 14B model requires complex parallelism infrastructure (CP, TP, FSDP, DeepSpeed). Helios is designed so that a full forward and backward pass fits on a single GPU without parallelism or sharding — achieved through aggressive token compression, which makes the 14B model comparable in memory usage to image generation models. Actual training across all three stages was conducted on 64–128 NVIDIA H100s.
How Helios architecture works
At the core of Helios is Unified History Injection — a way to turn a bidirectional pretrained model (Wan-2.1) into an autoregressive generator without losing quality. The idea is simple: the model always receives two chunks of video simultaneously — already-generated clean frames (historical context) and a noisy segment it needs to generate next. The task is to remove noise from the second chunk using the first as a reference.
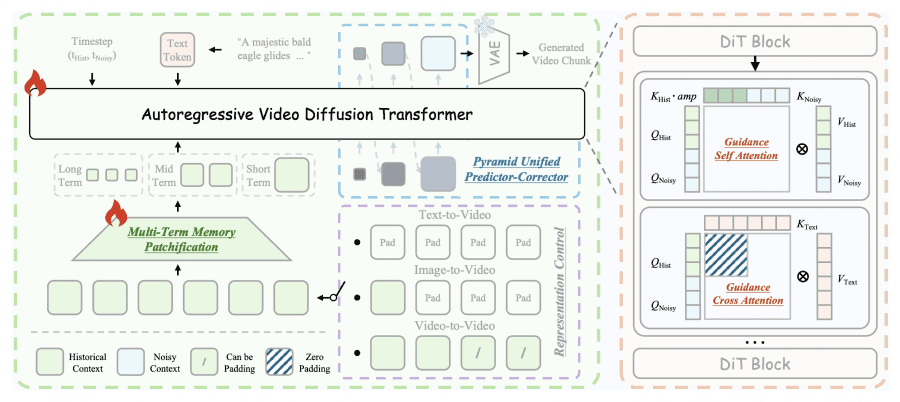
To ensure history actually helps generation rather than interfering with it, the authors designed Guidance Attention. In the self-attention mechanism, keys from the historical context are multiplied by learnable amplification coefficients — separate for each attention head. This lets the model decide which parts of the history matter and which to ignore. Cross-attention with the text prompt is applied only to the noisy segment — the historical context already incorporated the text in previous steps.
A separate technique — Representation Control — allows a single architecture to support three operating modes: if history is entirely zeroed out, the model works as text-to-video; if only the last frame is filled in — as image-to-video; if real video is passed in — as video-to-video.
How Helios fights error accumulation
The authors propose three simple techniques under the name Easy Anti-Drifting — without expensive strategies like self-forcing or error-banks.
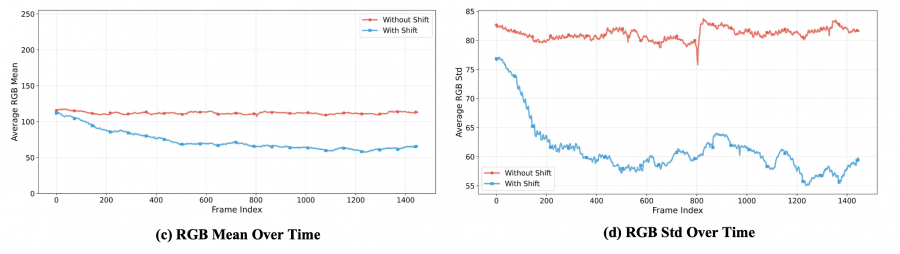
Relative RoPE rethinks positional encoding. Normally, when generating a 1440-frame video, the model sees absolute temporal indices 0–1399, even though it was only trained on short clips. Helios solves this simply: the historical context always receives indices from 0 to a fixed boundary, and the new generated segment gets the next few positions after it. Video length doesn’t matter — the window is always the same. This also eliminates the “looping” effect, where the model periodically returns to the same motions due to the mathematical periodicity of RoPE.
First-Frame Anchor — the first frame always stays in the historical context until the end of generation as a global visual anchor. The authors noticed that color degradation almost never starts from the earliest frames — meaning the first frame reliably “remembers” what the scene should look like.
Frame-Aware Corruption — during training, the model intentionally receives corrupted history: noise is added to frames with varying probabilities, exposure is changed, or downsampling is applied. This teaches the model not to blindly trust its own previous outputs, relying on deeper patterns rather than surface-level similarity to the history.

How Helios got fast: Deep Compression Flow
Speed is achieved through aggressive token compression at two levels.
Multi-Term Memory Patchification divides the historical context into three parts — short-term, medium-term, and long-term — and compresses them at different rates. Recent frames retain high resolution; older frames are heavily compressed. This is roughly analogous to how humans remember recent events in detail but distant ones only in broad strokes. The number of history tokens is reduced approximately 8×, while the total token budget stays constant regardless of video length.
Figure 7 (p. 8 of the paper): Multi-Term Memory Patchification. Left plot — token count; center — GPU memory; right — inference time. The naive approach (blue) quickly goes OOM; Helios (red) stays stable.
Pyramid Unified Predictor Corrector changes the diffusion sampling process itself. Instead of working at full resolution immediately, the model starts low — where the rough structure of the scene is determined — and gradually moves to higher resolution where details are refined. This reduces the number of tokens for the generated segment by approximately 2.3×.

Adversarial Hierarchical Distillation cuts sampling steps from 50 to 3. Instead of the standard Distribution Matching Distillation approach, the authors use the already-trained autoregressive Helios-Base as the teacher rather than a bidirectional model. This allows training the distilled version without expensive long rollouts — during training, only one segment per step needs to be generated.
Results
On the short video benchmark (81 frames), Helios-Distilled achieves a total score of 6.00, outperforming all distilled models and matching base models of similar size. The speed — 19.53 FPS on a single H100 — is out of reach for competitors at the same scale: FastVideo Wan2.1 and TurboDiffusion are 2–3× slower, and Wan 2.1 14B is 52× slower.
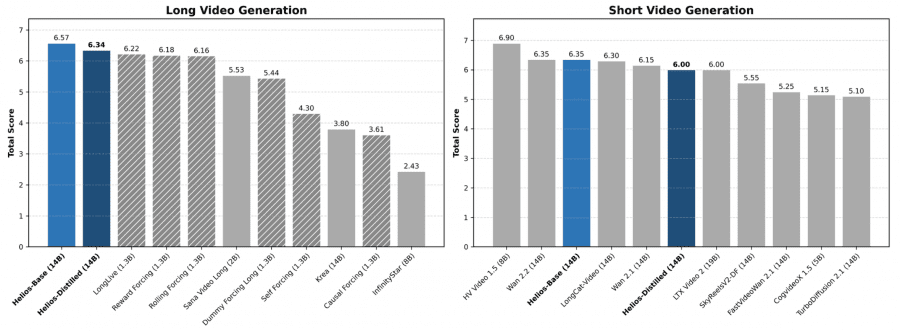
On long videos (up to 1440 frames, ~74 seconds at 19.5 FPS), Helios-Distilled scores 6.94, surpassing the best competitor Reward Forcing (6.88). Error accumulation in Helios is lower across most measured metrics — the model maintains scene identity and color consistency across hundreds and thousands of frames.
User testing (200 evaluators, 40 pairwise comparisons each) confirms the results: Helios wins in 70–92.5% of cases against competitors on long videos, and in 56–99.2% on short ones.
Ablation findings
The authors sequentially disabled each component and measured the degradation. Without First-Frame Anchor, the total score drops from 6.47 to 5.51; without Frame-Aware Corruption — to 4.70, with degradation appearing as early as frame 240. Adding a causal mask to Guidance Attention completely destabilizes training. Replacing the autoregressive teacher with the bidirectional one (Wan-2.1) drops the distilled model’s quality from 6.34 to 4.75.
Flash Normalization and Flash RoPE — custom Triton kernels for LayerNorm and positional encoding — together speed up inference by 14.4% and training by 14.5% compared to base Wan-2.1.
Limitations
The authors openly acknowledge several issues. All experiments are limited to 384×640 resolution due to computational constraints. Flickering artifacts sometimes appear at the boundaries between generated segments — a common problem for autoregressive models. Finally, standard metrics like Aesthetic and Smoothness correlate poorly with human perception, making objective comparison difficult. The authors consider developing perceptually aligned metrics an important direction for future work.





