NVIDIA has announced the open Llama Nemotron family of models with reasoning capabilities, designed to provide a business-ready foundation for creating advanced AI agents. These models can work independently or as connected teams to solve complex tasks, delivering on-demand AI reasoning with significant enhancements. Post-training by NVIDIA has improved accuracy by up to 20% compared to base models while achieving 5x faster inference speed compared to other leading open reasoning models. The models are specialized for multistep math, coding, reasoning, and complex decision-making tasks.
Llama Nemotron Nano 8B and Super 49B models are available through build.nvidia.com and Hugging Face.
Llama Nemotron Models in Detail
The Nano (8B) architecture is built on Meta’s Llama-3.1-8B-Instruct as a dense decoder-only Transformer with a context length of 131,072 tokens (128K). It’s designed for hardware compatibility with a single RTX GPU (30/40/50 Series), H100-80GB, or A100-80GB.
The Super (49B) architecture takes Meta’s Llama-3.3-70B-Instruct as its foundation but is customized through Neural Architecture Search (NAS). While maintaining the same 128K context length, it introduces innovative structural elements including skip attention (where some blocks have attention skipped or replaced with a linear layer) and variable FFN (with different expansion/compression ratios between blocks). This architecture is specifically optimized to fit on a single H100-80GB GPU.
The Ultra (253B) architecture is distilled from Llama 3.1 405B for maximum agentic accuracy on multi-GPU data center servers (coming soon).
Three-Phase Training Process
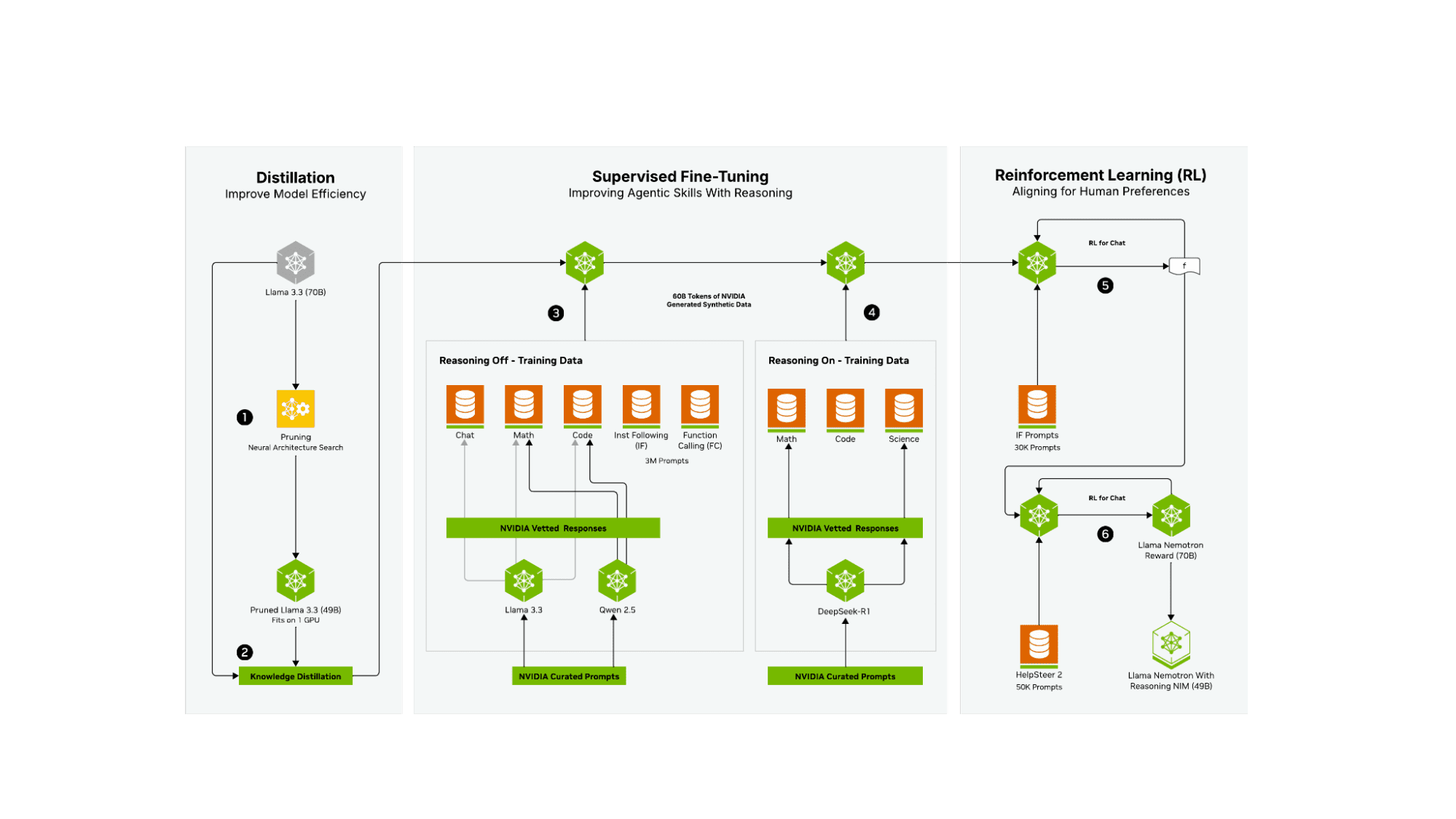
NVIDIA employed a sophisticated three-phase training process to develop these models.
- The distillation phase began with Llama 3.3 (70B) as the base model, applying Neural Architecture Search for model pruning followed by Knowledge Distillation to create a pruned 49B model that fits on a single GPU.
- The supervised fine-tuning phase focused on improving agentic skills with reasoning capabilities through two parallel training paths. The “Reasoning Off” path used data from Chat, Math, Code, Instruction Following, and Function Calling, while the “Reasoning On” path specifically targeted Math, Code, and Science tasks. Multiple models were leveraged to generate high-quality responses during this phase.
- Finally, the reinforcement learning phase aligned the model with human preferences through multiple RL iterations using IF Prompts (30K) and a final optimization incorporating HelpSteer 2 (50K prompts).
Llama Nemotron Performance Highlights
The models demonstrate significant performance improvements when reasoning mode is enabled. On the MATH500 benchmark (pass@1), the Nano model jumps from 36.6% to 95.4% with reasoning enabled, while the Super model improves from 74.0% to an impressive 96.6%. For MT-Bench, the Nano model scores 7.9 to 8.1 with reasoning, while the Super model achieves 9.17 in reasoning-off mode. Consistently across all benchmarks, the Super model outperforms its Nano counterpart.
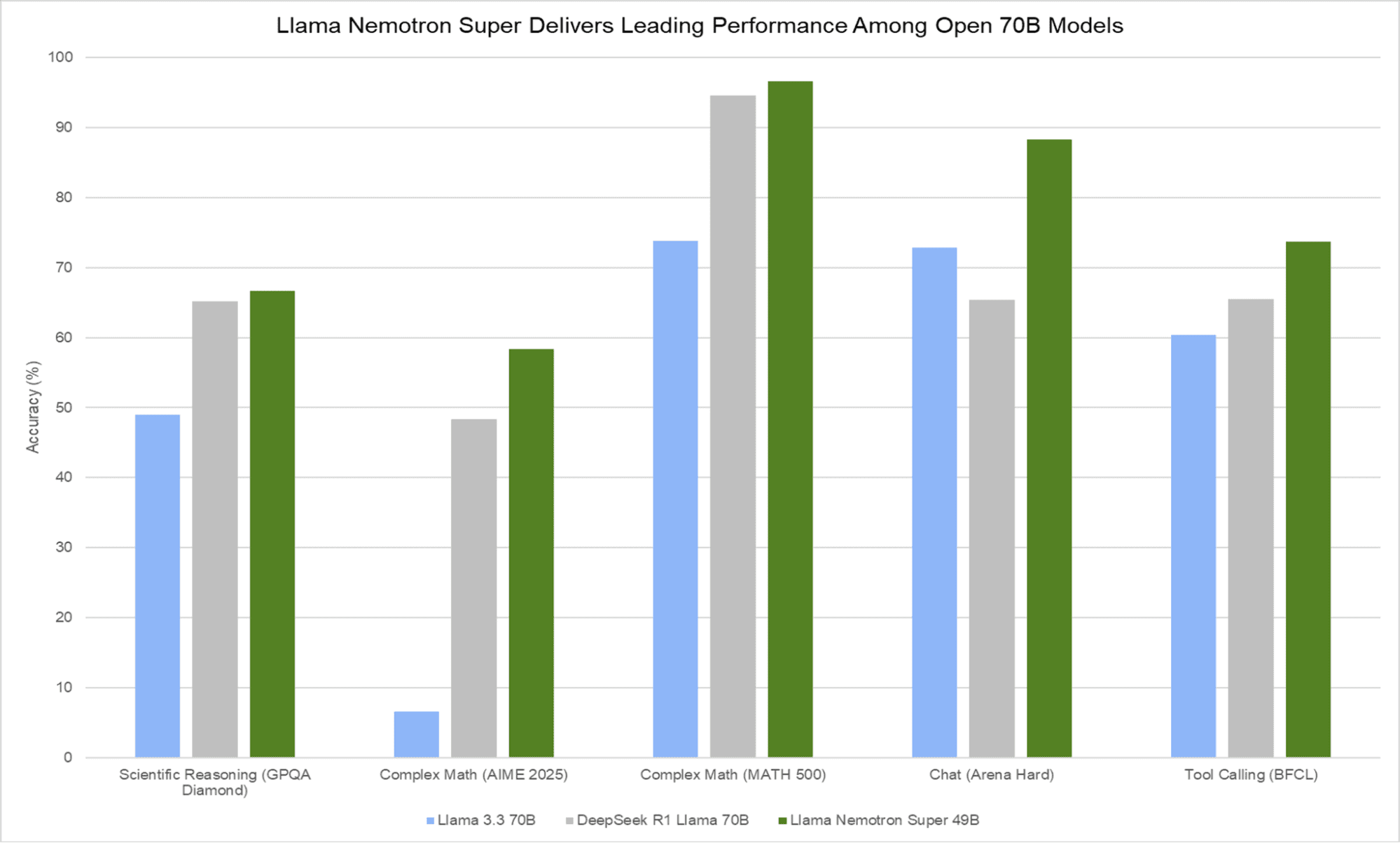
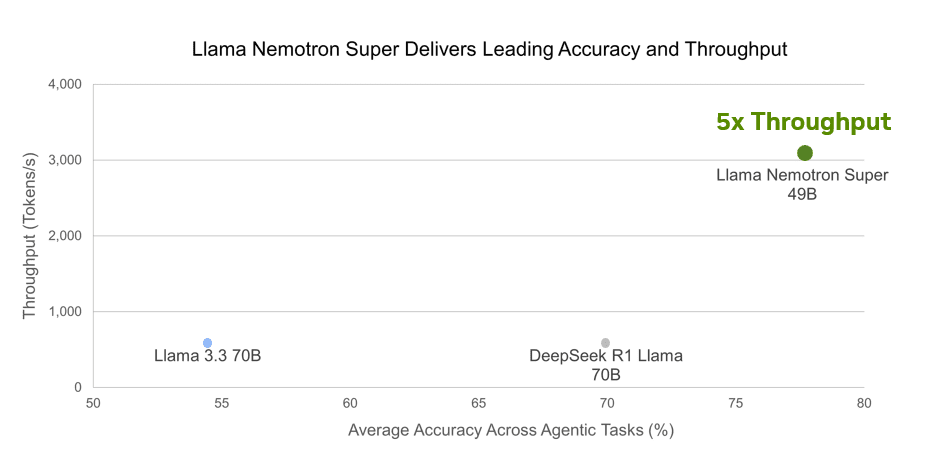
Usage and Access
Both models offer two operational modes controlled via the system prompt: “Reasoning On” (recommended settings: temperature=0.6, top_p=0.95) and “Reasoning Off” (recommended: greedy decoding). The models are available through build.nvidia.com and Hugging Face, with free access for development and research for NVIDIA Developer Program members, and production deployment via NVIDIA AI Enterprise. Additional resources include the AI-Q Blueprint (expected in April 2025) and the AgentIQ toolkit (available now on GitHub).
These models represent a significant advancement in making reasoning AI more accessible to developers and enterprises, providing the foundation needed to build sophisticated AI agent systems capable of solving complex problems.