
The OpenBMB research team presented MiniCPM4 — a highly efficient language model designed specifically for local devices. MiniCPM4-8B achieves comparable performance to Qwen3-8B (81.13 vs 80.55), while requiring 4.5 times fewer tokens for training: 8 trillion vs 36 trillion. On local devices, MiniCPM4 runs 7 times faster than Qwen3-8B when generating responses for 128K-token sequences. Efficiency is achieved through improvements in four key areas: trainable sparse attention InfLLM v2, data filtering UltraClean, optimized training algorithms ModelTunnel v2, and inference framework CPM.cu. The MiniCPM0.5B and MiniCPM8B models are released under Apache 2.0 license and available on GitHub, with weights published on Hugging Face.
Model Architecture
The MiniCPM4 developers applied a systematic approach, implementing innovations in four critical areas. The model architecture received a new mechanism InfLLM v2 — trainable sparse attention that accelerates both prefilling and decoding for long contexts. The system uses semantic kernels of 32 tokens with a stride of 16 for dynamic selection of relevant key-value blocks, achieving 81% attention sparsity without performance loss.

Improvements in training data processing are implemented through UltraClean — a filtering strategy that reduces verification costs from 1,200 to 110 GPU-hours. The system uses a pre-trained 1B model to assess data quality through a two-stage annealing process, while the FastText classifier processes 15 trillion tokens in 1,000 CPU-hours vs 6,000 GPU-hours for traditional approaches. UltraChat v2 complements the system with a dataset for supervised fine-tuning, including data for knowledge-intensive, reasoning-intensive, instruction following, long-context, and tool use scenarios.
Training algorithms were improved through ModelTunnel v2, which uses ScalingBench as a performance indicator, establishing a sigmoid relationship between loss function and downstream task performance. Chunk-wise rollout for balanced reinforcement learning provides 60% reduction in sampling time.

The CPM.cu inference framework integrates sparse attention, model quantization, and speculative sampling. FR-Spec reduces vocabulary by 75% for draft generation acceleration, P-GPTQ provides prefix-aware quantization, and ArkInfer supports cross-platform deployment.
Results
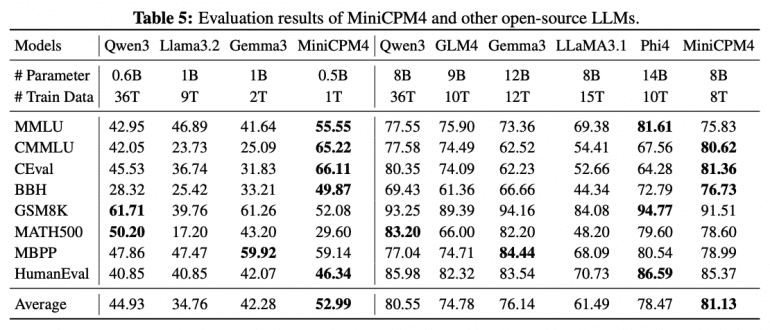
Experimental results convincingly demonstrate the effectiveness of the approach. MiniCPM4-0.5B achieves an average score of 52.99 vs 44.93 for Qwen3-0.6B, while MiniCPM4-8B shows 81.13 vs 80.55 for Qwen3-8B. The training efficiency appears revolutionary: MiniCPM4 achieves comparable performance using only 8 trillion tokens vs 36 trillion for Qwen3-8B — just 22% of the original data volume.
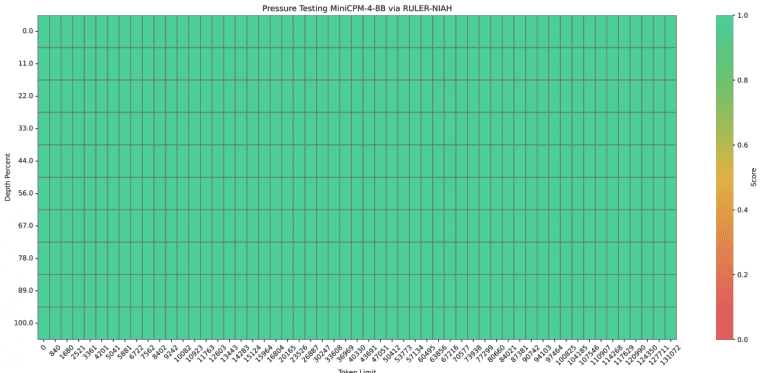
Inference performance demonstrates impressive results. On the Jetson AGX Orin platform when processing 128K context, MiniCPM4 provides seven-fold acceleration relative to Qwen3-8B. The system successfully handles extremely long contexts, achieving 100% accuracy in the RULER-NIAH test when processing up to 128K tokens with extrapolation from base 32K.
Real-world Applications
The practical value of MiniCPM4 is confirmed through specialized models. MiniCPM4-Survey for scientific review generation uses Plan-Retrieve-Write architecture, achieving Content Quality 3.50 and a record Fact Score of 68.73, surpassing even OpenAI Deep Research on factual metrics.
MiniCPM4-MCP is adapted for Model Context Protocol work and demonstrates outstanding results:
function name accuracy: 88.3%;
parameter name accuracy: 76.1%.
The model was trained on 140,000 examples of tool calling data through the MCP protocol and outperforms the baseline Qwen3-8B model on all key metrics. The system supports compatibility with 16 different MCP servers, including Airbnb, GitHub, Slack, PPT, and Calculator, providing broad integration with existing development tools.
MiniCPM4 is released in two configurations with 0.5B and 8B parameters, enabling optimal deployment on resource-constrained devices. The research demonstrates the possibility of creating highly efficient language models through comprehensive optimization of architecture, data, algorithms, and inference systems, opening prospects for accessible artificial intelligence.






