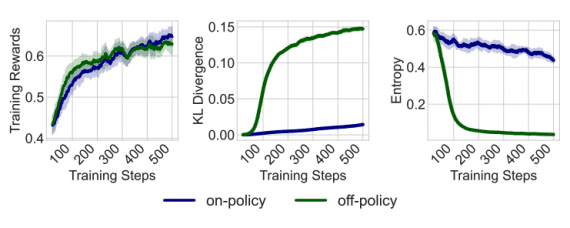
Microsoft recently unveiled Phi-4-reasoning, a 14-billion parameter model that achieves exceptional performance on complex reasoning tasks, outperforming models 5-47 times larger while requiring significantly less computational resources, with developers able to access the model directly through Microsoft’s Hugging Face repository and GitHub Models. The model is now officially available on GitHub Models, where developers can try it in the playground or implement it through the GitHub API The GitHub Blog. This advancement represents a major leap in Microsoft’s AI capabilities and challenges the notion that bigger models are always better.
The Technical Innovation
Phi-4-reasoning maintains the same architecture as the base Phi-4 model with two crucial modifications. The team repurposed placeholder tokens as special markers (<think> and </think>) to delineate reasoning sections, allowing the model to explicitly separate its thinking process from its final answers. They also expanded the token context length from 16K to 32K, giving the model more space to develop extended chains of thought. These architectural adaptations, combined with carefully crafted training data, unlocked remarkable new capabilities.
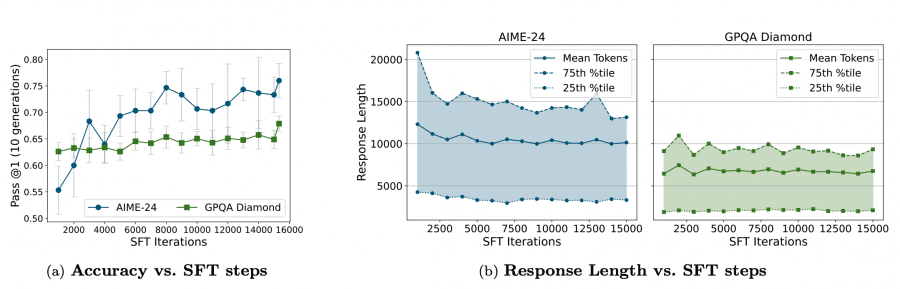
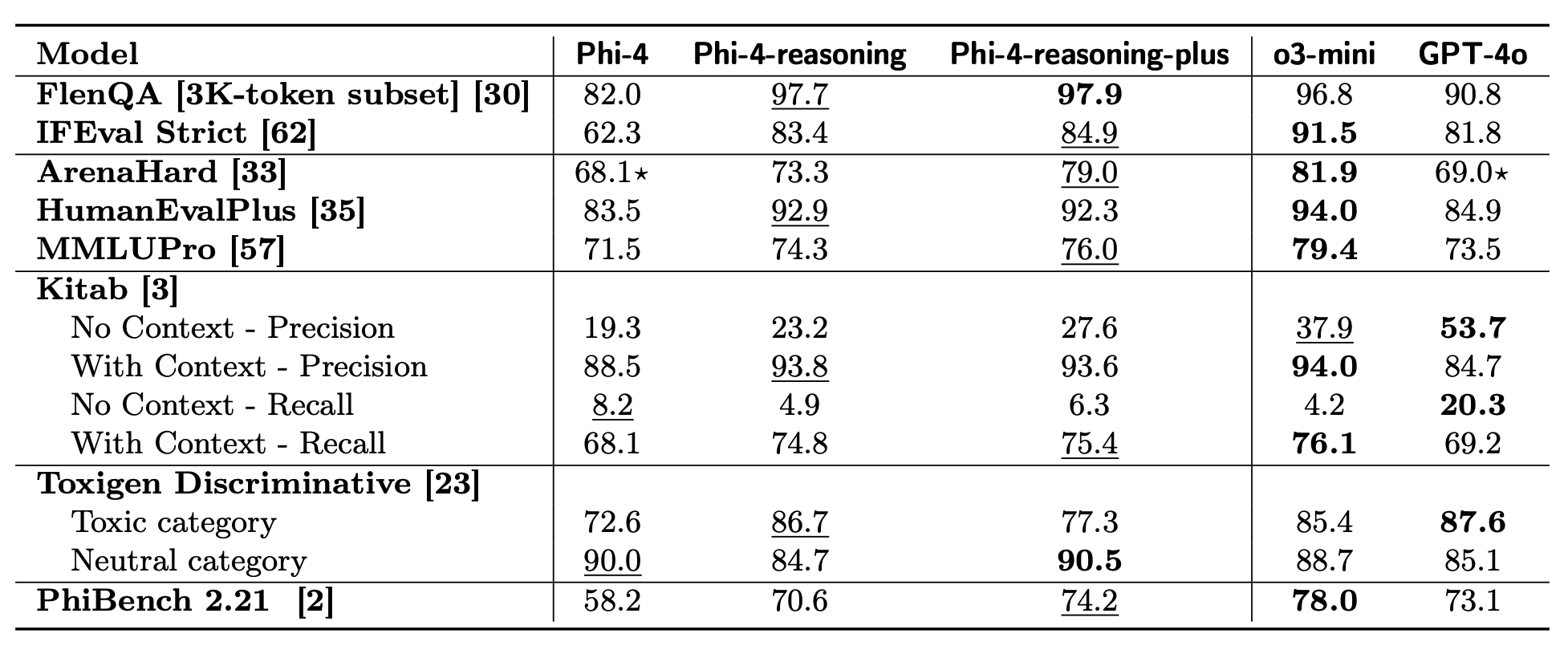
The development journey didn’t stop there. Microsoft also created Phi-4-reasoning-plus, which underwent additional reinforcement learning training on mathematical problems. This enhanced variant produces longer, more thorough reasoning traces, resulting in 15% higher accuracy on AIME 2025 and 5% better performance on OmniMath benchmarks.
Impressive Performance Metrics
The performance improvements over the base Phi-4 model are striking:
- Mathematical reasoning: +50 percentage points on AIME 2025 (12.9% → 78.0%)
- Coding ability: +25 points on LiveCodeBench (28.0% → 53.8%)
- Algorithmic problem-solving: +30-60 points on tasks like TSP, 3SAT, and Calendar Planning
- General capabilities: +22 points in instruction following, +16 points in long-context QA, +10 points in chat interactions
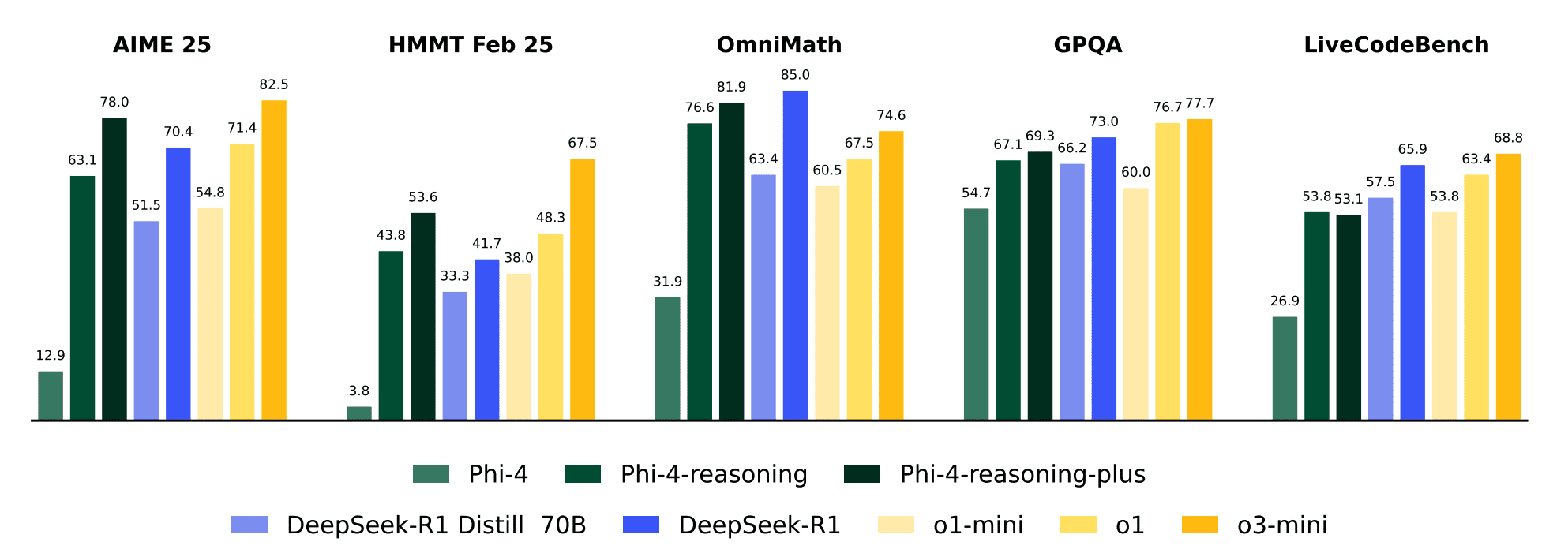
Despite its relatively modest 14B parameter size, Phi-4-reasoning-plus competes effectively with industry giants like DeepSeek-R1 (671B parameters) and outperforms o1-mini and DeepSeek-R1-Distill-Llama-70B on most benchmarks.
The Data-Centric Approach
The secret behind these impressive results lies in Microsoft’s data-centric approach. Rather than simply scaling up model size, the team meticulously curated over 1.4 million prompt-response pairs that push the boundaries of what Phi-4 could already do. They focused on problems that demand multi-step reasoning rather than simple fact recall, creating a training dataset that specifically targets reasoning as a skill.
For Phi-4-reasoning-plus, they implemented reinforcement learning on 6,400 carefully selected mathematical problems using Group Relative Policy Optimization (GRPO). This additional step taught the model to explore multiple solution paths before committing to an answer, further enhancing its reasoning capabilities.
Beyond Specialized Tasks
Perhaps most remarkably, the improvements in reasoning capabilities generalized beyond specialized tasks to enhance overall intelligence. Instruction following, long-context question answering, chat interactions, and even toxic content detection all saw substantial improvements. This suggests that teaching a model to reason more carefully improves its general capabilities, not just its performance in narrow domains.
Microsoft’s Phi-4-reasoning models demonstrate that the future of AI advancement may not lie solely in building ever-larger neural networks, but in teaching more modest models to think more effectively—much as humans develop expertise through focused practice rather than simply growing larger brains. It’s a compelling case for working smarter rather than just bigger in the pursuit of more capable AI systems.