Researchers from Fudan University and StepFun have published PixelSmile — a diffusion model for precise facial expression editing in portraits and anime images. Instead of training on discrete labels like “fear/not fear”, the model uses continuous numerical intensity scores and symmetric contrastive learning, which teaches the model to distinguish similar emotions in both directions: if fear differs from surprise, then surprise must also differ from fear. PixelSmile doesn’t just add an emotion — it smoothly controls the degree of its intensity. The project is fully open: code on GitHub, weights on Hugging Face under the Apache 2.0 license, and a live online demo.
The Problem with Existing Approaches
The human face is structured in a way that anger and disgust often look very similar: furrowed brows, tense gaze, general expression of displeasure. When a generative model is trained on binary labels, it receives contradictory examples and its latent space becomes entangled — when trying to generate anger, the model partially generates disgust as well.
This is called semantic overlap or feature entanglement. In feature space, neighboring emotions lie too close together without a clear boundary between them. The authors confirmed this experimentally: human annotators, classifiers, and generative models all systematically confuse the same pairs of emotions. A neural network classifier assigns a fear score of 0.95 to a photo of a surprised person — confidently mistaking surprise for fear.
The FFE Dataset
The first step proposed by the researchers is replacing discrete labels with numerical vectors. To this end, the authors created the FFE (Flex Facial Expression) dataset, containing 60,000 images across two domains: real portraits and anime characters. Instead of a single label, each image is assigned a 12-dimensional vector of emotion intensity scores — one number from 0 to 1 for each of the 12 emotions. For example, a photo might receive “happiness” 0.85, “confidence” 0.55, and near-zero scores for all other categories.
The dataset was built in four stages: collecting base identities (approximately 6,000 real portraits and 6,000 anime characters from 207 anime productions), constructing a library of text prompts for 12 emotions, generating images at varying intensities using the Nano Banana Pro editing model, and finally — automatic annotation using Gemini 3 Pro with partial verification by human annotators. This produced continuous soft labels that honestly reflect semantic overlap between emotions rather than concealing it.
Alongside the dataset, the authors created the FFE-Bench benchmark with four metrics:
- mSCR (Mean Structural Confusion Rate) — the lower, the better the model separates similar emotions;
- HES (Harmonic Editing Score) — penalizes the model if it edits the expression well but distorts the person’s appearance, or vice versa. A high score requires both criteria to be met simultaneously;
- CLS (Control Linearity Score) — the Pearson correlation between the specified intensity coefficient α and the predicted intensity: the higher, the more predictably the model behaves;
- Acc — the proportion of generated images where the predicted dominant emotion matched the target.
FFE-Bench contains 198 evaluation tasks (98 real portraits and 100 anime) and is available on Hugging Face. The evaluation code will be published in the GitHub repository.
How PixelSmile Works
PixelSmile is built on Qwen-Image-Edit-2511 — an open diffusion model from Alibaba for text-guided image editing. The input is a single RGB image with a face and the name of the target emotion. The output is an edited image of the same resolution. No reference images are needed — everything is controlled via the intensity coefficient α.
The architecture builds on a pretrained Multi-Modal Diffusion Transformer (MMDiT) with LoRA. The key idea lies in how PixelSmile controls emotion intensity at inference time and how it trains on semantically similar emotions.
Textual latent interpolation. At inference time, no reference images are needed. A neutral text prompt and a target expression prompt are both passed through the encoder to produce two embeddings. Linear interpolation is then performed between them using a coefficient α from 0 to 1: at α=0 the face remains neutral, at α=1 the expression reaches maximum intensity. At α > 1, an even stronger expression can be obtained, and the authors show this works without losing structural consistency.
Fully symmetric joint training. This is the main technical contribution. Standard contrastive learning is asymmetric: sample A is the anchor, B is the positive, C is the negative. But applying this in only one direction for the “fear/surprise” pair means the model treats these emotions differently. The authors train in both directions simultaneously: in one pass, fear is positive and surprise is negative; in the next, the roles are swapped. This eliminates directional bias and forces the model to clearly separate both emotions equally.
The full loss function consists of three components: flow-matching loss (aligns visual intensity with the α coefficient from continuous annotations), symmetric contrastive loss (separates semantically similar emotions in the CLIP encoder feature space), and identity loss based on ArcFace (prevents the model from drifting to a different appearance under strong editing).
Experimental Results
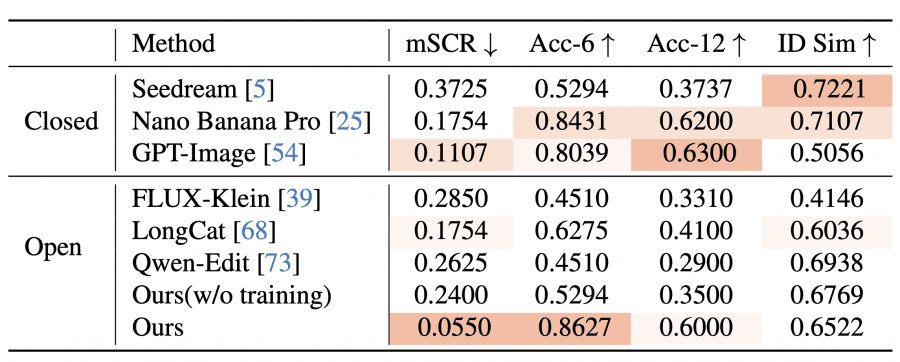
All quantitative results were obtained on FFE-Bench. The authors compared PixelSmile against two groups of baselines. The first group — general-purpose AI editors: Nano Banana Pro, GPT-Image-1.5, Seedream-4.5 (closed) and Qwen-Image-Edit, FLUX-Klein, LongCat (open). The second group — methods for linear attribute control: K-Slider, SliderEdit, ConceptSlider, AttributeControl.
For editing accuracy on six basic emotions, PixelSmile achieves 0.8627 — the best result among all models, above Nano Banana Pro (0.8431) and GPT-Image (0.8039). But the most telling result is on the semantic confusion metric mSCR: PixelSmile reaches 0.0550, while GPT-Image scores 0.1107, Nano Banana Pro 0.1754, and most other models exceed 0.2000. An mSCR value close to 0.5 means the model essentially collapses two semantically similar emotions into one — failing to distinguish them at all.
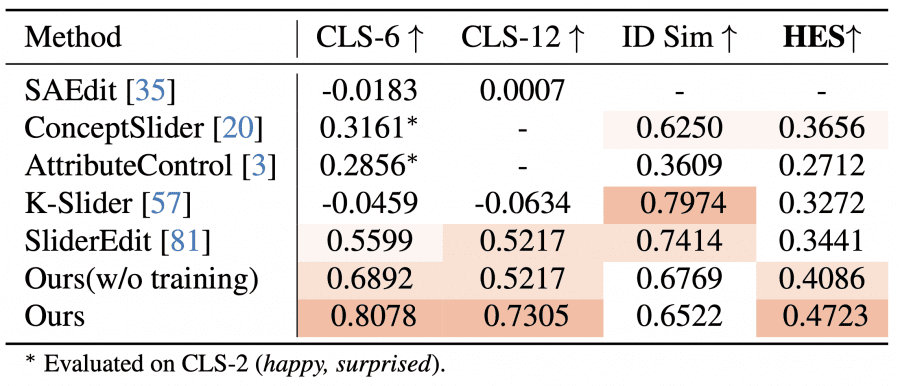
Against linear control methods, PixelSmile achieves CLS-6 = 0.8078 and HES = 0.4723 — again the best results. Notable issues with competitors: K-Slider has a negative CLS, meaning intensity doesn’t grow monotonically but fluctuates chaotically with increasing α. SliderEdit rapidly loses similarity to the original (ID similarity drops to ~0.4) once the emotion reaches medium intensity. PixelSmile, in contrast, maintains ID similarity in the 0.6–0.7 range at expression scores up to ~0.8 — corresponding to the realistic range described in the literature.
Expression Blending as a Side Effect
Since the model is trained to control the intensity of each of the 12 emotions independently, it can be asked to move toward two different emotions simultaneously — and see what happens. The authors tested all 15 pairwise combinations of the six basic emotions. In 9 out of 15 cases the result looked coherent — for example, “happiness + surprise” produces something like joyful astonishment, and “sadness + disgust” yields a kind of disgusted melancholy. The remaining 6 combinations either collapsed into one dominant emotion (fear + surprise are too similar to blend), or produced a physically impossible expression — for example, anger and happiness simultaneously. This suggests the model didn’t just memorize templates for what anger looks like, but genuinely learned how emotions relate to each other in the space of human facial expressions.
User Study
A user study with 10 trained annotators evaluated three methods: PixelSmile, K-Slider, and SliderEdit. Two criteria were assessed — continuity of changes and identity preservation — on a scale of 1 to 5. PixelSmile scored (4.48, 3.80) — the best balance. K-Slider scored (1.36, 4.06): preserves identity well but produces barely noticeable changes. SliderEdit scored (3.16, 1.14): changes expressions but strongly distorts identity. This aligns with automatic metrics and confirms that HES works correctly as an evaluation metric.
How to Run
PixelSmile is built on top of Qwen-Image-Edit-2511 — an open diffusion model from Alibaba for text-guided image editing. This is a Multi-Modal Diffusion Transformer (MMDiT) that takes a source image and a text prompt and returns an edited image. Version 2511 features improved character consistency, reduced image drift, and built-in LoRA support. The model is released under Apache 2.0 and downloaded separately from Hugging Face. On top of it sits the PixelSmile LoRA adapter — the file PixelSmile-preview.safetensors (~4 MB), which handles controllable expression editing.
The input is a single image with a face and the name of the target emotion. The output is one or more images (one per specified α value) at the same resolution with the modified expression. No reference images are needed.
Installation (Python 3.10, conda):
git clone https://github.com/Ammmob/PixelSmile.git
cd PixelSmile
conda create -n pixelsmile python=3.10
conda activate pixelsmile
pip install -r requirements.txt
bash scripts/patch_qwen_diffusers.shThe last command is a required patch to fix a bug in the current version of diffusers when working with Qwen-Image-Edit. Without it, inference will not run.
Two ways to run inference are supported. Option 1 — using default arguments that can be edited directly in the script:
bash scripts/run_infer.shOption 2 — passing explicit arguments from the command line:
bash scripts/run_infer.sh
--image-path /path/to/input.jpg
--output-dir /path/to/output
--model-path /path/to/Qwen-Image-Edit-2511
--lora-path /path/to/PixelSmile.safetensors
--expression happy
--scales 0 0.5 1.0 1.5
--seed 42The --scales parameter sets the α values — the model will generate one image per value. At α=0 the face remains neutral, at α=1 the expression is at full intensity, and at α=1.5 the emotion is amplified beyond the training range. The default is 50 inference steps, as visible in the online demo. All 12 expressions are supported: happy, sad, angry, surprised, fear, disgust, anxious, contempt, confident, shy, sleepy, confused.
At the time of publication, only a preview version of the weights is available, covering the real portrait domain only. Anime support and a more stable version have been announced. Training requires additional dependencies (pip install -r requirements-train.txt) and auxiliary weights, the full list of which the authors plan to publish separately. Training was conducted on 4 × NVIDIA H200.
Conclusion
PixelSmile addresses a longstanding problem in generative models: their inability to clearly distinguish semantically similar emotions. Replacing discrete labels with continuous annotations plus symmetric contrastive learning produces a model that simultaneously outperforms closed commercial editors on expression separation accuracy and outperforms specialized linear control methods on predictability and stability of intensity control.