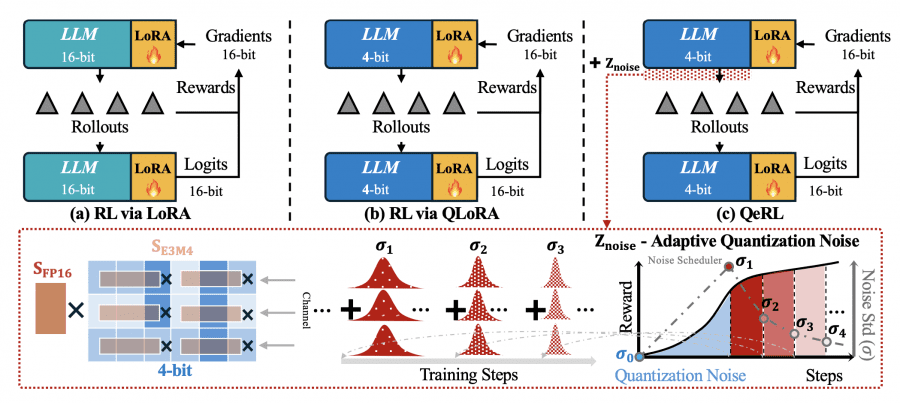
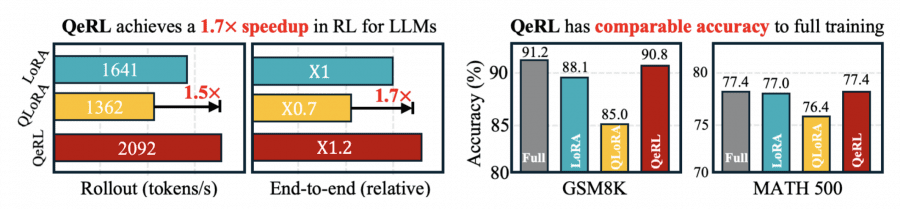
QeRL is a framework for training language models using reinforcement learning that simultaneously reduces GPU requirements and surpasses traditional LoRA and QLoRA methods in accuracy. On the Qwen2.5-7B-Instruct model, QeRL achieves 90.8% accuracy on the GSM8K mathematical benchmark versus 88.1% for 16-bit LoRA and 85.0% for QLoRA, while being 1.5-2× faster. For the first time, it has become possible to train a 32-billion parameter model with reinforcement learning on a single H100 GPU, instead of the 2-3 GPUs required by standard approaches.
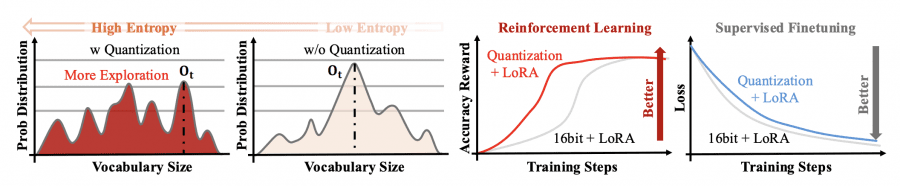
Quantization noise, traditionally considered a drawback, improves the model’s ability to find more effective problem-solving strategies in the RL context. This explains why quantized models show not only comparable but superior accuracy compared to full-precision counterparts. QeRL combines NVFP4 quantization with Low-Rank Adaptation (LoRA), accelerating the critical rollout phase and reducing memory consumption by 50-60%.
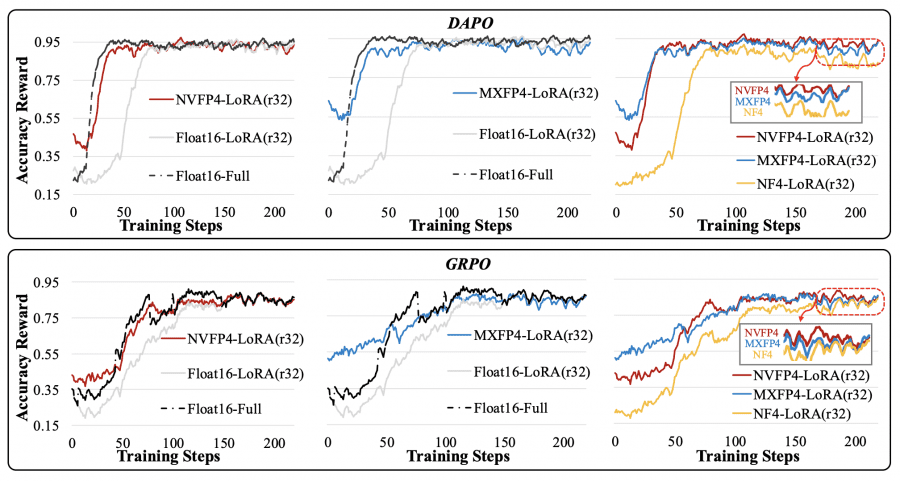
Comparison with LoRA and QLoRA
The rollout phase (sample generation) is the stage of reinforcement learning when the model creates multiple answer variants for each input query. For example, the model receives a mathematical problem and must generate 8-16 different solutions, each up to several thousand tokens long. This phase takes up most of the training time.
LoRA (Low-Rank Adaptation) reduces the number of trainable parameters through decomposition W + ΔW = W + BA, where only low-rank matrices A and B are updated instead of the full weight matrix. This accelerates the gradient update stage but creates the main problem—slow sample generation. The model still operates in 16-bit precision, requiring full GPU memory for inference.
QLoRA attempts to solve the memory problem by integrating LoRA with 4-bit NF4 quantization. However, the approach creates a new problem: NF4 requires unpacking values through a lookup table before each matrix multiplication, which slows down generation by 1.5–2×. The paradox is that memory savings come at the cost of increased training time.
How QeRL Surpasses Its Predecessors
QeRL uses NVFP4 quantization—a 4-bit floating-point format with built-in hardware support in Hopper and Blackwell GPU architectures. Unlike NF4, NVFP4 doesn’t require slow unpacking through lookup tables. The format uses FP8 (E4M3) scaling factors with 16-element blocks, enabling fine-grained scaling while maintaining computational speed.
Integration with the Marlin kernel accelerates matrix multiplication for quantized weights. During rollout, the model operates entirely in 4-bit precision, reducing memory usage by 2-3×. Gradient backpropagation occurs through LoRA adapters in 16-bit precision, maintaining training stability.
A key finding by the researchers: quantization noise, traditionally considered a drawback, becomes an advantage in the RL context. The quantized model introduces small systematic errors during the forward pass that increase entropy in the probability distribution over tokens. Instead of concentrating probability on a single “optimal” token, the model considers a broader spectrum of options, improving exploration—the search for better problem-solving strategies.
To optimize exploration, QeRL introduces Adaptive Quantization Noise (AQN)—a mechanism for dynamically adjusting noise levels during training. In early stages, high noise levels stimulate broad exploration of the solution space. As training progresses, noise gradually decreases following an exponential schedule: σ(k) = σ_start · (σ_end/σ_start)^((k-1)/(K-1)), allowing the model to focus on exploiting discovered strategies.
Technically, noise is integrated into RMSNorm parameters without additional parameters: w_noise = Z_noise + w, where Z_noise is a random vector sampled at each forward pass. Channel-wise additive noise transforms into row-wise multiplicative noise in the weight matrix, avoiding compatibility issues with NVFP4 × BF16 operations.
Experimental Results
Experiments on mathematical datasets GSM8K and BigMath demonstrate QeRL’s significant advantages. On Qwen2.5-7B-Instruct trained with GRPO on GSM8K:
- LoRA (16-bit): 88.1% accuracy
- QLoRA (NF4): 85.0% accuracy
- QeRL (NVFP4): 90.8% accuracy
QeRL surpasses LoRA by 2.7 points and QLoRA by 5.8 points. Moreover, QeRL achieves results comparable to full-parameter fine-tuning (91.2%) while training only 1% of parameters.
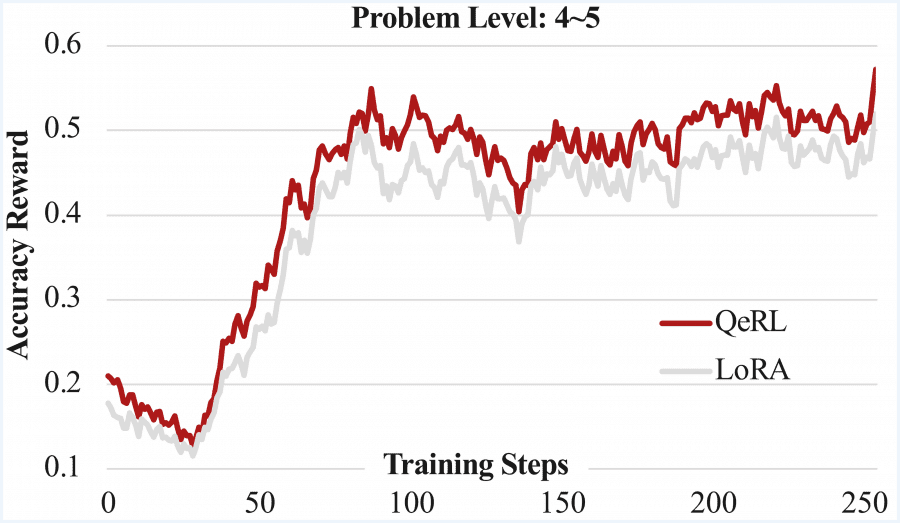
On the more challenging BigMath dataset with difficulty levels 3-5, the 7B model improves average score from 25.7 (baseline quantized model) to 36.4, surpassing vanilla LoRA’s 35.7. For the 14B model on the AMC 23 dataset, QeRL reaches 57.5, even exceeding full-parameter training (55.0).
In rollout speed, QeRL demonstrates substantial acceleration. For the 7B model with batch size 8, throughput is 2091.8 tokens/s versus 1641.1 for LoRA—a 1.3× speedup. QLoRA shows only 0.7× of LoRA’s speed due to slow NF4 unpacking. End-to-end training acceleration is 1.1-1.2× for the 7B model and 1.3-1.4× for the 14B model.
For the 32B model, the difference is even more dramatic: QeRL achieves 2× rollout acceleration. Critically, QeRL enables training a 32B model on a single H100 80GB GPU, while vanilla LoRA requires 2-3 GPUs due to memory constraints.
Practical Value
Typical RL training for reasoning models takes 20-100 hours on 8× H100 GPUs. QeRL reduces this to 60-80 hours, saving 1-2 days per experiment. With H100 cloud costs of $2-4 per GPU-hour, savings amount to approximately $1,000 per experiment or $10,000-$50,000 for a complete research project with multiple iterations.
The main advantage is lowering the barrier for training large models. A 32B model can now be trained on one GPU instead of 2-3, reducing the entry threshold for small research groups and startups. QeRL uses only 40-50% of vanilla LoRA’s GPU memory, opening possibilities for experiments on more accessible hardware.
The framework is released under an open license on GitHub. The methodology applies not only to mathematical problems but also to other domains requiring multi-step reasoning—programming, scientific reasoning, and action planning.







