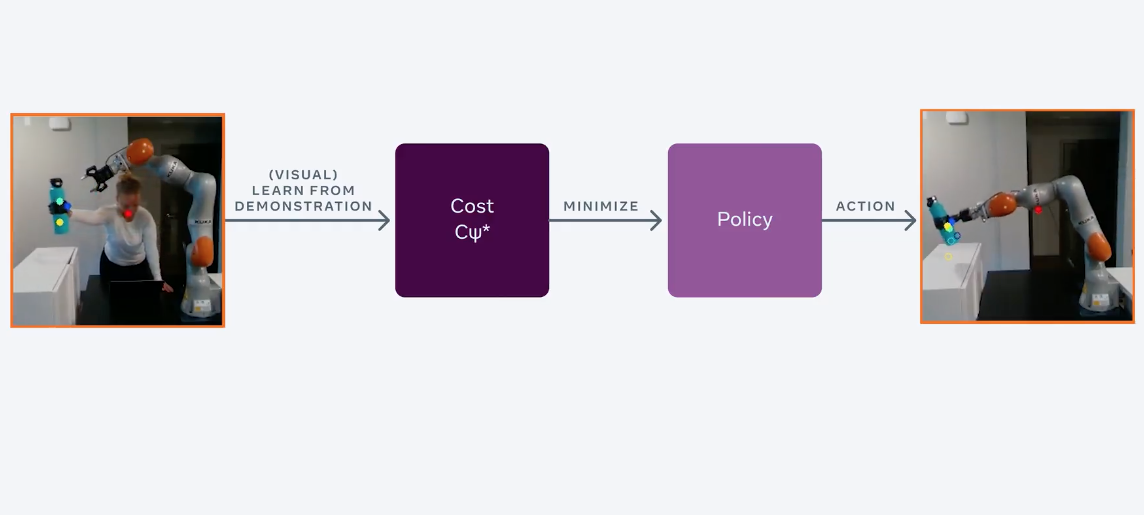
In FAIR, the RL-agent was trained to manage objects using video tutorials. Standard RL algorithms are trained to a problem iteratively through learning from errors. The proposed algorithm learns a model of the environment, observes human behavior, and then determines the reward function. This approach to training RL agents is called Model-Based Inverse Reinforcement Learning (MBIRL).
Why is it needed
People easily learn new simple tasks like picking up and placing an object on the table through visual demonstrations. However, robots, in order to learn how to solve the same problems, require manually assigned reward functions for each individual problem. To train a robot to place a bottle on a table, you first need to set a reward for moving the bottle over the table. Then – a reward for the fact that the robot puts the bottle on the table. It is a slow iterative process that does not relate to the real world, where agents must constantly learn new simple tasks. Researchers at FAIR have reformulated the approach to training RL agents so that the robot learns to perform new tasks using short video clips.
More about the approach
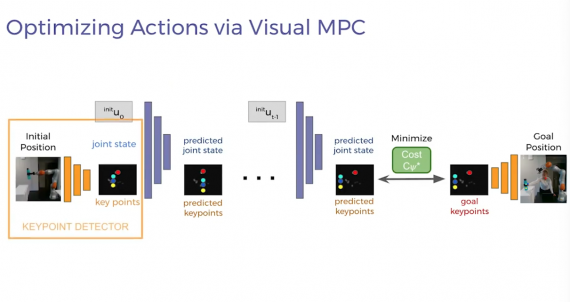
An important part of the proposed approach is a model that predicts changes in what is observed. Most of the previous work assumes that a dynamic model of the environment is known, so the researchers first teach the robot to learn the model of the environment using cue point detectors. Such detectors are trained in a self-supervised format, which eliminates the cost of marking up training data and makes the robot more resistant to environmental changes.

The detectors extract small-sized visual cues from human and robot motion demos. Then a model is pre-trained so that the robot can predict how its actions will change this small-sized representation. The robot can optimize its behavior policy using its visual dynamic model so as to maximize its reward functionality. Gradient descent is used as an optimization algorithm.