DeepMind has introduced the RETRO language model, which implements a learning scheme based on the use of external memory. RETRO demonstrates results comparable to GPT-3, despite the fact that it has 25 times fewer parameters.
In the two years since OpenAI released its GPT-3 language model, most major companies, including Google, Microsoft and several Chinese corporations, have created their own analogues that can generate text, communicate with people, answer questions and much more.
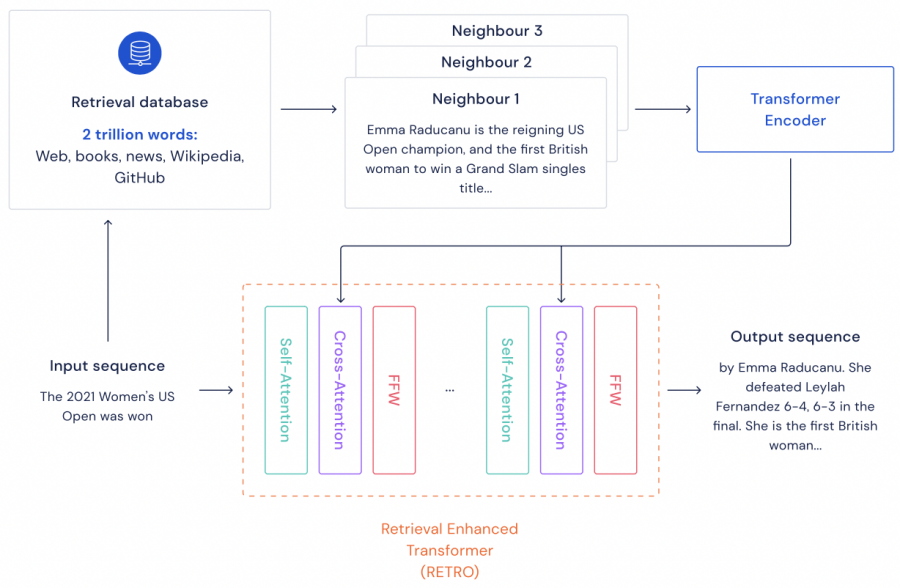
Called RETRO (Retrieval-Enhanced Transformer), the DeepMind model demonstrates efficiency comparable to neural networks that are 25 times larger than RETRO. This reduces the costs required to train models. A feature of the DeepMind model is external memory in the form of an extensive database containing text fragments, which it uses as a cheat sheet when creating new sentences. DeepMind developers claim that the database facilitates the analysis of what their model has learned, for the subsequent fight against bias.
Language models generate text by predicting which words will be next in a sentence or conversation. The larger the model, the more information it can learn during training, which makes its predictions better. For example, GPT-3 has 175 billion parameters, and the Microsoft model has 530 billion parameters. But large models also require huge computing power for training.
Using RETRO, DeepMind tries to reduce training costs without reducing the size of the training sample. The researchers trained the model on a dataset consisting of news articles, Wikipedia texts, books and text from GitHub. The dataset contains texts in 10 languages, including English, Spanish, German, French, Russian, Chinese, Swahili and Urdu.
The RETRO neural network has only 7 billion parameters. But the system compensates for this with a database containing about 2 trillion text passages. The neural network and the database are trained simultaneously.
When RETRO generates text, it uses a database to search and compare passages similar to the one he writes, which makes his predictions more accurate. Outsourcing part of the neural network memory to the database allows RETRO to use less computing resources.
The database can also be updated without retraining the neural network. This means that new information can be quickly added, and outdated or false information can be deleted. DeepMind claims that systems such as RETRO are more transparent compared to black box models such as GPT-3.


