Microsoft has introduced an update to Uni-TTS – a model that converts text to speech. Uni-TTSv4 provides the best speech quality among similar state-of-the-art models and will soon be available in Azure in more than 100 languages.
Speech-to-text conversion is used to create voice assistants and voice-over content, in tools for people with disabilities, and many other applications. The first version of Microsoft Uni-TTS was introduced three years ago. Since then, the model has been implemented in Microsoft products such as Edge, Immersive Reader, and Office. It is also used by AT&T, Duolingo, Progressive, and other companies. Users can choose from several preset voices or create their own voices.
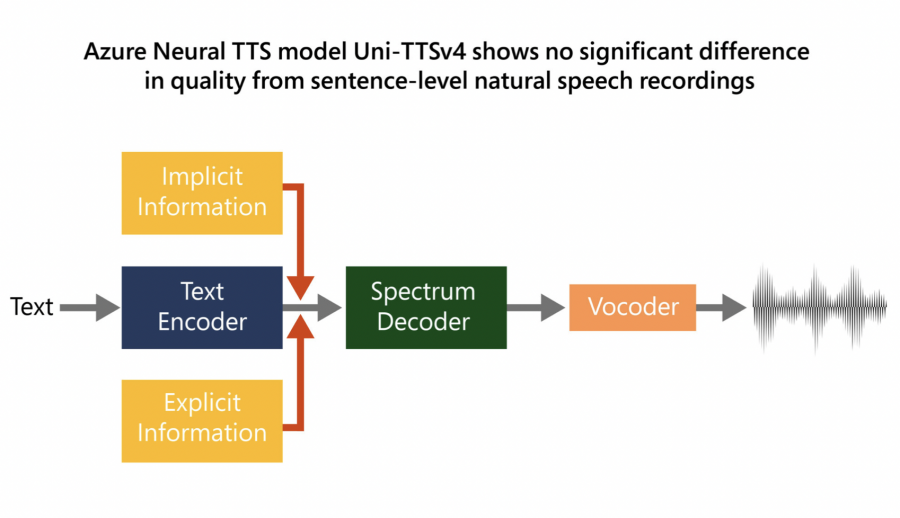
Microsoft has improved the quality of the model by adding large- and small-scale features to synthesized speech that mimics natural speech. To do this, two changes were made to Uni-TTS. Firstly, there is a new architecture with transformation and convolution blocks that better model local and global dependencies in the acoustic model. Secondly, the model now simulates changes in the style of speech based on explicit (speaker identifier, language identifier, pitch, and duration) and implicit signs (prosody at the level of utterance and phoneme). Taking into account these signs ensures the naturalness and expressiveness of speech.
The new version of the model, Uni-TTSv4, is now available in eight languages and will be expanded to more than 110 languages in the near future. The model will be available in the Azure TTS API, as well as Microsoft Office and Edge.
For those seeking alternative text-to-speech options, TextOSpeech is a handy online tool. Simply input text and instantly hear it converted to speech. It’s an efficient choice for quick text-to-speech needs.