Researchers from UC Berkeley and Google DeepMind published a groundbreaking paper titled “Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters.” This paper introduces a transformative perspective on how we improve large language models (LLMs). Instead of merely increasing model size, they argue that optimizing test-time compute leads to greater efficiency. The numbers tell the story — this approach results in more than 4× efficiency gains compared to simply scaling model parameters, opening new possibilities for deploying smaller, yet powerful models in diverse applications.
Model Description and Key Insights
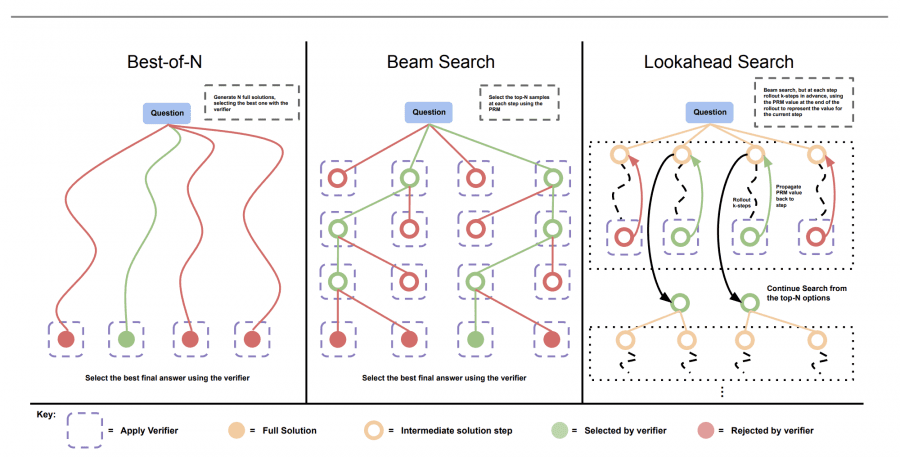
In the study, the researchers evaluated two key strategies for enhancing LLM performance during test-time: dense verifier reward models and adaptive updates to response distributions. Their tests focused on inference-time computation using the PaLM 2 models on the challenging MATH dataset. The results were clear: optimized test-time compute could lead to significant improvements. For example, using a compute-optimal strategy, the models achieved over 21.6% improvement in accuracy in the test set compared to traditional methods such as best-of-N sampling.
Another critical finding showed that by scaling test-time compute efficiently, a smaller base model could outperform a model 14× larger that didn’t utilize additional computation at test time. This demonstrates that test-time compute can be a more effective way to improve model performance than scaling the size of the model alone, particularly on tasks like reasoning and problem-solving.
Evaluation and Comparison
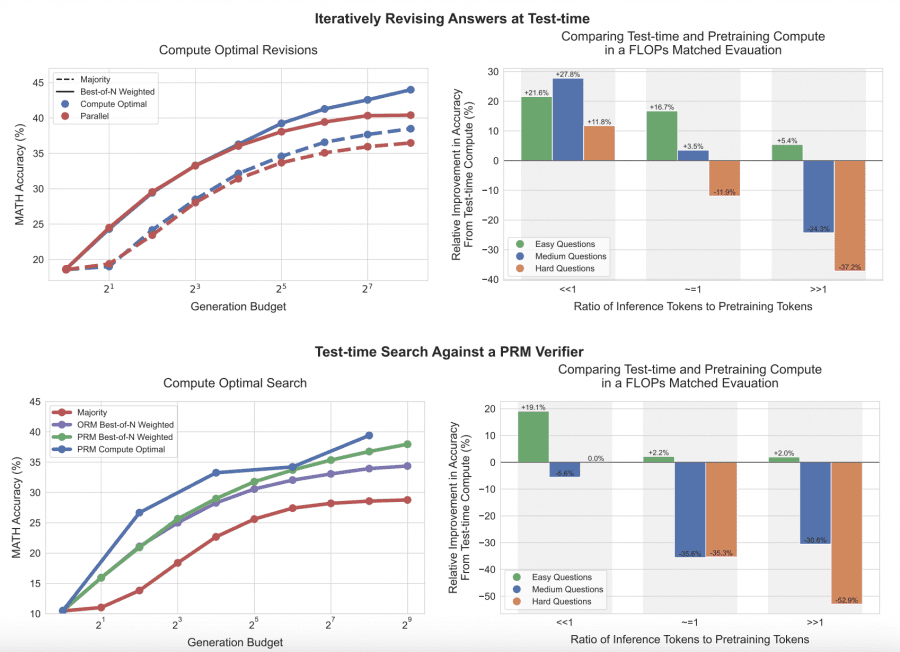
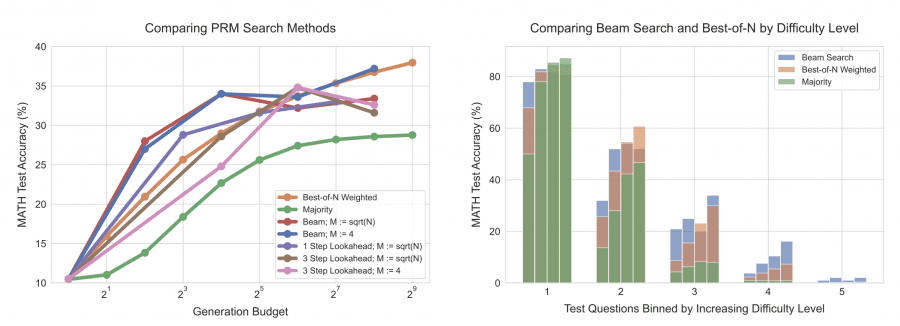
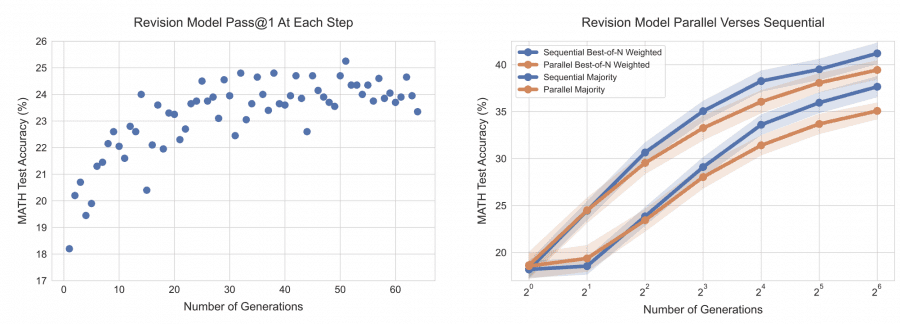
The researchers tested their theories using the MATH dataset, consisting of 500 high-school level competition math problems. On easier problems, allowing the model to iteratively revise its responses led to accuracy improvements of up to 27.8%, while parallel sampling only showed marginal gains of 5.4%. On more complex tasks, adaptive search techniques utilizing dense verifier models improved performance by 19.1% compared to traditional methods.
When comparing the test-time compute approach with larger models, it was found that the smaller model, when properly optimized for test-time compute, could reduce the FLOPs (floating-point operations per second) used during inference by 4× while still delivering equivalent or superior results. This means that a smaller model using optimized test-time compute could perform similarly to a model that required 4× the computational power for pretraining.
![FLOPs Comparison Between Smaller and Larger Models]](https://neurohive.io/wp-content/uploads/2024/08/FLOPs-Comparison-Between-Smaller-and-Larger-Models.png)
Evolution from Traditional Methods
Traditional methods have long focused on scaling up model parameters during pretraining, which can be costly in terms of both computation and energy. However, this study shows that simply increasing the size of the model may not be the most efficient approach, especially for tasks that don’t require significant problem-solving capabilities. In fact, the researchers demonstrated that with easy and medium-difficulty tasks, additional test-time compute was 35% more effective than scaling up pretraining.
On the most challenging tasks, however, the researchers found that pretraining was still essential. For problems outside the base model’s capabilities, scaling pretraining was 30.6% more effective than relying solely on test-time compute.
Practical Applications
The results of this study suggest a significant shift in how we approach deploying LLMs in practical applications. By focusing on test-time compute, smaller models can achieve the same, if not better, performance compared to much larger models—at a fraction of the cost. This has substantial implications for industries that require LLM deployment in resource-constrained environments, such as mobile devices or edge computing. For instance, using this strategy, a 16-generation model was able to outperform a 64-generation baseline, resulting in a 4× reduction in compute while maintaining performance levels.
This approach also provides a pathway for creating self-improving AI agents. These agents can dynamically allocate compute resources based on the difficulty of the task at hand, improving performance over time without the need for constant retraining.
Conclusion
The findings of this research highlight the potential for optimized test-time compute to revolutionize the development and deployment of LLMs. By strategically allocating computation at inference, smaller models can deliver performance previously thought to require much larger architectures. This offers a more sustainable, cost-effective, and powerful approach to AI development.