
The research team from ByteDance Seed in collaboration with the AIR Institute of Tsinghua University introduced Seed Diffusion Preview — a language model based on discrete diffusion that demonstrates record-breaking inference speed. The model achieves 2,146 tokens per second on H20 GPUs while maintaining competitive performance on code generation benchmarks. Seed Diffusion Preview represents a new state-of-the-art on the speed-quality Pareto frontier for code generation models. The model can be tested in an interactive demo.
Seed Diffusion Architecture
Seed Diffusion Preview applies discrete-state diffusion instead of traditional autoregressive token-by-token decoding. This architectural feature allows the model to generate tokens in parallel, significantly accelerating inference compared to traditional autoregressive models.
The model is based on a standard dense Transformer architecture optimized for code generation tasks. Researchers deliberately excluded complex reasoning components, focusing on creating an efficient baseline system with maximum inference speed.
TSC: Two-Stage Training Process
The key methodological innovation is TSC (Two-Stage Curriculum), representing a structured training approach with two types of data augmentation processes in forward diffusion.
Mask-based corruption: During the first 80% of training steps, a standard masking strategy is applied, gradually replacing tokens in the dataset with a special [MASK] token. The process is controlled by a noise function that determines what proportion of tokens should be masked at each training stage. This function sets probability distributions for preserving the original token or replacing it with [MASK] at each sequence position, gradually increasing the degree of masking as the diffusion process progresses.
Edit-based augmentation: During the final 20% of training steps, data corruption is added through simulation of real code editing operations as an additional regularization technique. Instead of simple masking, the system applies more natural transformations: deleting code parts, inserting new fragments, or replacing existing elements. The intensity of these changes is controlled through Levenshtein distance — a metric measuring the minimum number of editing operations needed to transform the original code into a modified version. This allows the model to learn to restore code after various types of real edits that programmers perform in daily work.
The final loss function combines two training components: ELBO (Evidence Lower Bound) — a mathematical criterion for evaluating the quality of masked token restoration, and a denoising loss function — a metric for successful code restoration after editing operations. This combined architecture allows the model to simultaneously learn to handle simple corruptions (missing fragments) and complex realistic changes (code edits), making the system more robust and versatile when working with various types of incomplete or corrupted input data.
Trajectory Optimization and Constrained Sampling
From the multitude of possible code restoration methods, the model first generates a large number of variants (generation trajectories), then selects only the most effective ones based on the mathematical ELBO criterion. These best generation strategies form a dataset for final model fine-tuning, allowing it to learn optimal code restoration paths instead of random approaches.
Reinforcement Learning for Inference Acceleration
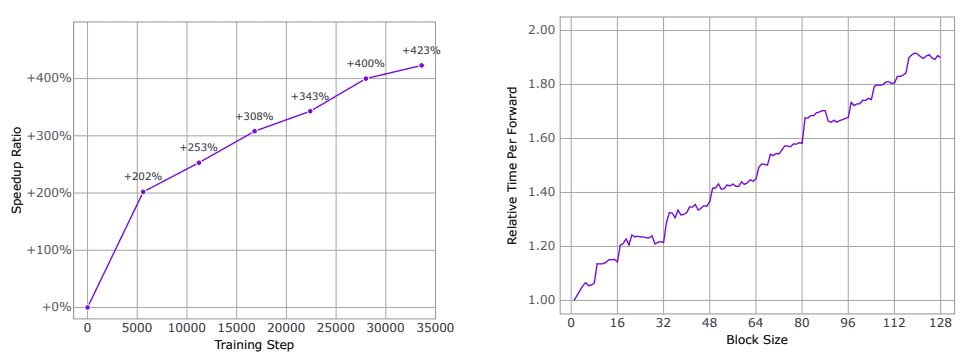
To maximize parallel processing capabilities, researchers apply reinforcement learning aimed at reducing the number of restoration steps. The system learns to generate code in the minimum number of iterations through gradual optimization of an auxiliary loss function. The result is impressive: the model’s inference speed increases by more than 4 times (400%+) during training, as confirmed by experimental measurements.
Block-wise Parallel Inference
For optimal balance between computational costs and latency, block-level parallel diffusion sampling with causal ordering between blocks is applied. The system uses key-value caching for previously generated blocks, ensuring inference efficiency without significant quality degradation in the generation process.
Seed Diffusion Results and Comparisons with Other Models
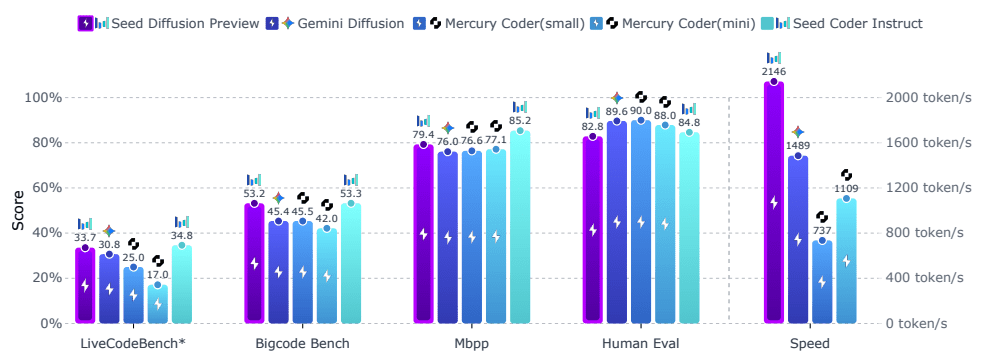
Seed Diffusion Preview demonstrates competitive performance on a comprehensive suite of code generation evaluation benchmarks.
Inference speed: 2,146 tokens per second on H20 GPUs — approximately twice as fast as Mercury Coder (1,109 t/s) and 1.5 times faster than Gemini Diffusion (1,489 t/s).
Performance metrics on benchmarks:
- HumanEval: 84.8% accuracy
- MBPP: 88.0% accuracy
- BigCodeBench: 45.4% success rate
- LiveCodeBench: 33.7% pass rate
On specialized code editing tasks, the model shows particularly strong results:
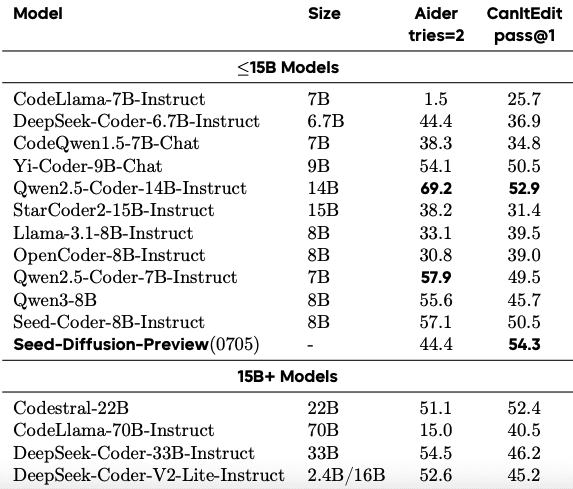
- Aider benchmark: 44.4% success rate (tries=2 setting)
- CanItEdit: 54.3% pass@1 metric
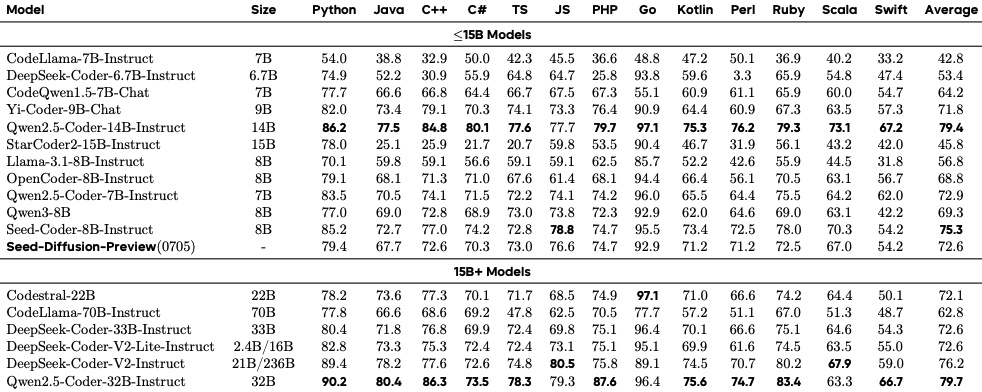
On the multilingual MBXP benchmark, Seed Diffusion Preview achieves an average score of 72.6%, demonstrating consistent performance across 13 programming languages from Python (79.4%) to Swift (54.2%).
The research confirms the practical applicability of discrete diffusion for real-world code generation applications. The method provides an optimal balance of speed and quality, critical for deployment in enterprise environments.





