
Arcee AI has released Trinity-Large-Thinking — an open-weight reasoning model for complex multi-turn agentic tasks. On PinchBench — a comprehensive benchmark for AI agents — it ranks second among all existing models, trailing only Claude Opus-4.6, while costing 28 times less. The project is fully open: model weights are available on Hugging Face under the Apache 2.0 license. Any developer or company can download, fine-tune, quantize, and deploy the model on their own infrastructure without any restrictions. You can try the model right now via OpenRouter or as a chatbot.
Where the model came from
Arcee AI is a small American lab from San Francisco that nine months ago made an unusual decision: to train foundation models from scratch rather than fine-tuning someone else’s. The company raised a $24M Series A in 2024, bringing total funding to around $50M. Against that backdrop, committing $20M — nearly half of all capital raised — to a single 33-day training run was a serious bet.
The run was executed on a cluster of 2,048 NVIDIA B300 Blackwell GPUs, which are roughly twice as fast as the previous Hopper generation. Prime Intellect handled compute infrastructure, while DatologyAI curated the training data.
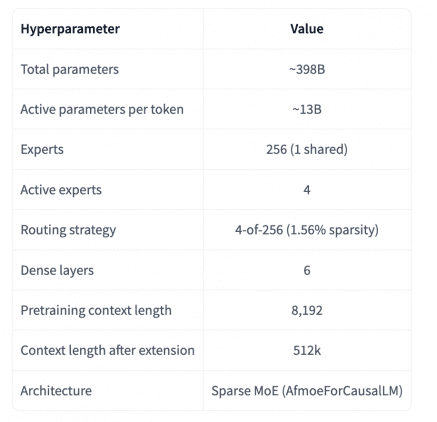
The result is the Trinity family: first came the smaller variants Nano (6B parameters) and Mini (26B), then in late January 2026 — Trinity-Large-Preview with light post-training. Now comes the final reasoning version — Trinity-Large-Thinking.
Architecture: sparse MoE with 400 billion parameters
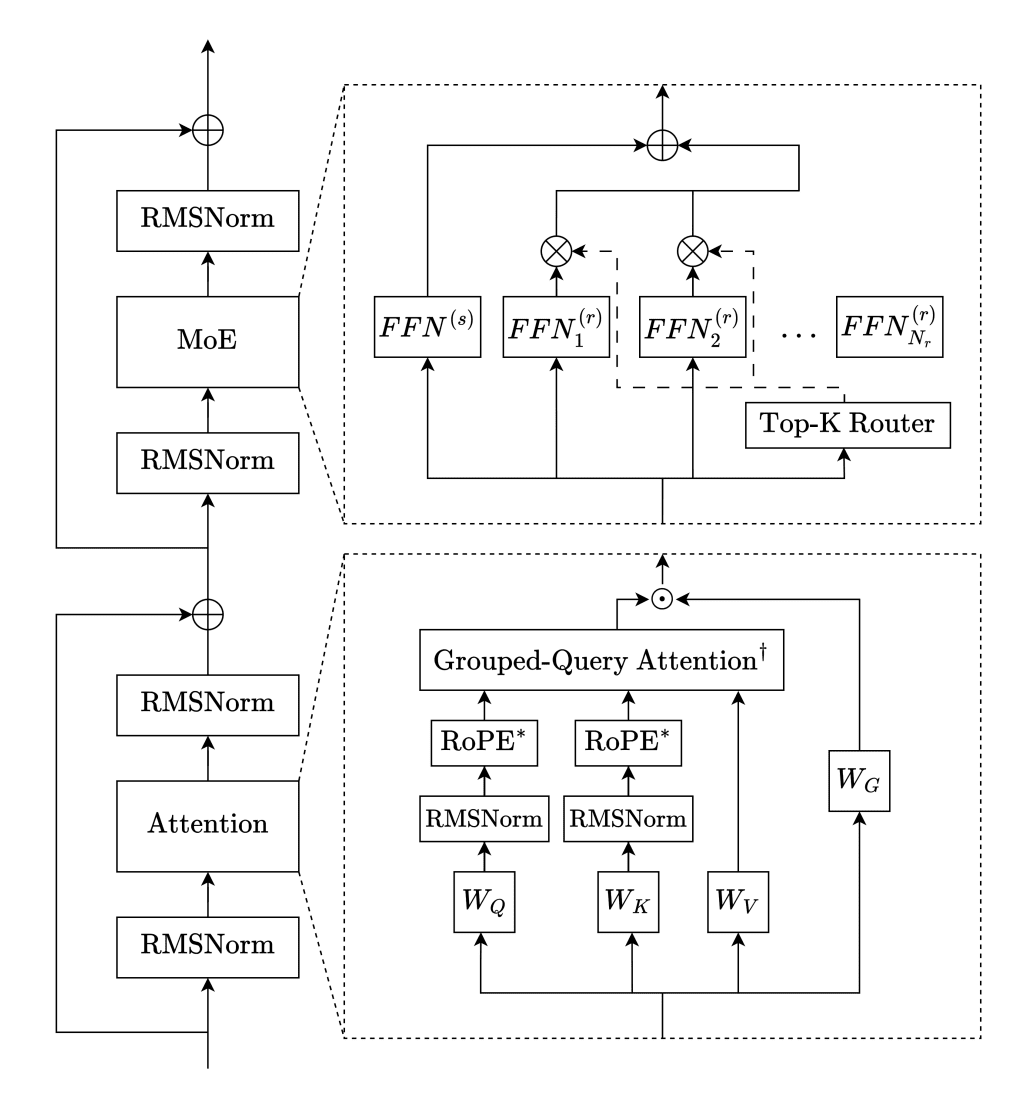
Trinity-Large-Thinking is built on the Sparse Mixture-of-Experts (MoE) architecture. The idea behind MoE is that the model contains many specialized “expert” subnetworks, but only activates a few of them when processing each token. This allows the model to have enormous capacity while keeping inference compute costs relatively low.
The sparsity ratio of 1.56% is one of the highest among publicly known MoE models. For comparison: DeepSeek-V3 and MiniMax-M2 use an 8-of-256 routing scheme (3.13% activation), Qwen3-235B uses 8-of-128 (6.25%). Llama 4 Maverick is slightly sparser than Trinity (0.78%), but all other competitors activate proportionally more parameters.
High sparsity is not just an architectural choice — it’s a direct consequence of the team’s economic constraints. The fewer parameters activated per forward pass, the faster inference runs and the faster rollouts proceed during reinforcement learning training. According to Arcee, Trinity-Large runs approximately 2–3x faster than comparably sized models on the same hardware.
Attention mechanism
Another source of speed is an unconventional attention scheme. Instead of every layer attending to the full context, Trinity alternates local and global layers in a 3:1 ratio: three local layers with sliding window attention and one global layer without positional embeddings. Local layers use RoPE and process only the nearest context within the window; global layers see the entire sequence. This split allows the model to handle long contexts efficiently without quadratic growth in compute. Additionally, all layers use gated attention — an elementwise multiplication of the attention output by a sigmoid gate — which according to the technical report reduces the occurrence of attention sinks (tokens that disproportionately attract attention) and further stabilizes training.
An interesting detail from the technical report: the model was trained on a 256k token context, but on the MK-NIAH test at 512k length it still scored 0.976 out of 1.0. This means it reliably handles contexts twice as long as what it was trained on.
Optimizer and training stability
For hidden layers, the team used the Muon optimizer instead of the standard AdamW. Its main advantage is a higher critical batch size and better sample efficiency — in other words, Muon extracts more value from each training step given the same number of tokens.
To keep routing stable and prevent expert load imbalance at such high sparsity, the team developed several technical solutions. The SMEBU algorithm (Soft-clamped Momentum Expert Bias Updates) is a new load balancing method for experts: each expert’s bias is adjusted based on how over- or under-utilized it is, with a tanh function capping the magnitude of each update. In addition to batch-level balancing, a separate sequence-level auxiliary loss is used. Z-loss regularization is also applied to prevent logits (raw outputs of the final layer before softmax) from growing unbounded during training.
The team also developed a new batching method — RSDB (Random Sequential Document Buffer). The standard sequence packing approach causes long documents to appear in consecutive batches, creating domain imbalance at the minibatch level. RSDB addresses this by randomly interleaving tokens from different documents when constructing each sequence. According to the technical report, enabling RSDB reduced gradient instability by 12.8x — the kurtosis of the gradient norm dropped from 187 to 14.6.
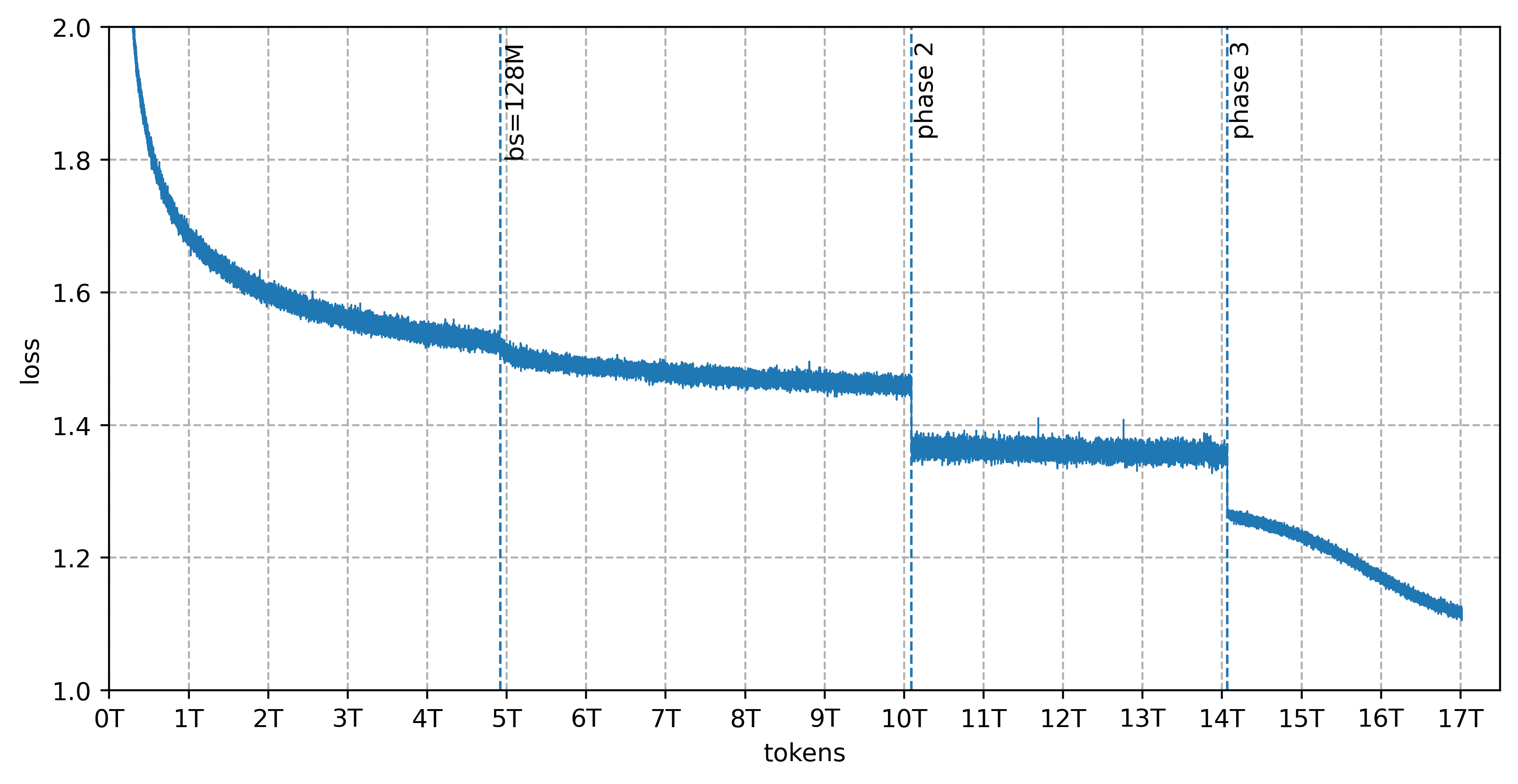
Training data
Pretraining was conducted on 17 trillion tokens curated by DatologyAI across three phases: 13T → 4T → 3T tokens (the full dataset totaled 20T; Trinity Large was trained on 17T sampled proportionally). The dataset covers 14 languages besides English — Arabic, Chinese, Japanese, Spanish, German, French, Italian, Portuguese, Indonesian, Russian, Vietnamese, Hindi, Korean, and Bengali — with a focus on programming, mathematics, natural sciences, reasoning tasks, and translation. Of the 17 trillion tokens, more than 8 trillion are synthetic: 6.5T of synthetic web content, around 1T of multilingual text, and around 800B tokens of code, all generated using various rephrasing approaches.
Post-training: from Preview to Thinking
Trinity-Large-Preview, released in January 2026, was a lightweight instruct model without reasoning: it could follow instructions, write, generate code, and work within agentic frameworks. In its first two months on OpenRouter, the model served 3.37 trillion tokens and became the #1 most-used open model in the US.
Trinity-Large-Thinking represents a fundamentally different training approach. The key difference: the model now uses an extended chain of thought before responding — everything it “thinks” is wrapped in <think>...</think> tags. In addition, the model underwent reinforcement learning on agentic tasks: tool calling, multi-step planning, and instruction following across long agentic loops.
An important technical note: tokens from the <think> block must be preserved in the context history during long conversations. Removing them to save context window space causes the model to lose its reasoning thread and degrade in quality. This is a critical requirement when building agentic systems on top of this model.
Benchmarks
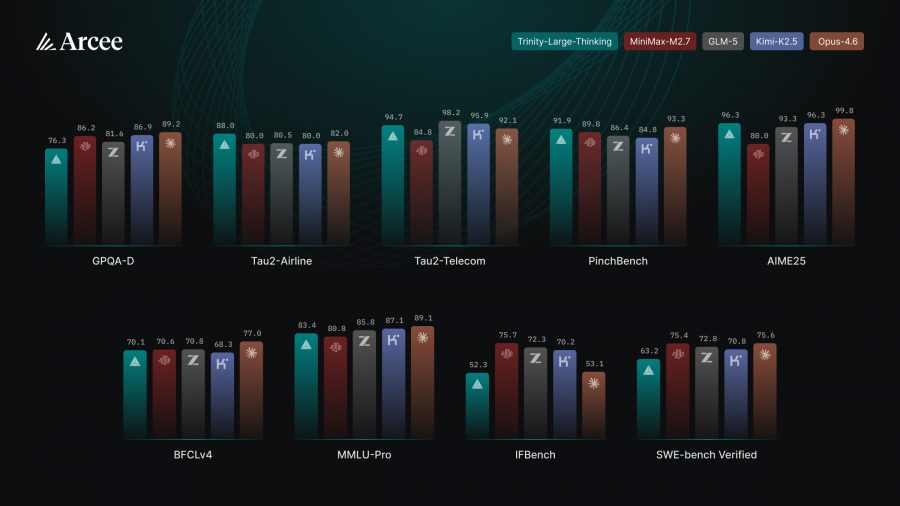
| Benchmark | Trinity-Large-Thinking | Opus-4.6 | GLM-5 | MiniMax-M2.7 | Kimi-K2.5 |
|---|---|---|---|---|---|
| IFBench | 52.3 | 53.1 | 72.3 | 75.7 | 70.2 |
| GPQA-Diamond | 76.3 | 89.2 | 81.6 | 86.2 | 86.9 |
| τ²-bench Airline | 88.0 | 82.0 | 80.5 | 80.0 | 80.0 |
| τ²-bench Telecom | 94.7 | 92.1 | 98.2 | 84.8 | 95.9 |
| PinchBench | 91.9 | 93.3 | 86.4 | 89.8 | 84.8 |
| AIME 2025 | 96.3 | 99.8 | 93.3 | 80.0 | 96.3 |
| BCFLv4 | 70.1 | 77.0 | 70.8 | 70.6 | 68.3 |
| MMLU-Pro | 83.4 | 89.1 | 85.8 | 80.8 | 87.1 |
| SWE-bench Verified* | 63.2 | 75.6 | 72.8 | 75.4 | 70.8 |
*All models evaluated using mini-swe-agent-v2
What these benchmarks mean in practice: PinchBench from Kilo evaluates model behavior in real agentic workloads, closely mirroring how developers use AI agents in tools like Cline and OpenClaw. τ²-bench is a benchmark for conversational agents across two domains — airline and telecom — where both the agent and the user can call tools and modify the state of a shared environment. GPQA-Diamond contains expert-level questions in physics, chemistry, and biology. AIME 2025 consists of problems from the American mathematics olympiad. SWE-bench Verified covers automated resolution of real GitHub issues in open-source projects.
Trinity-Large-Thinking ranks second on PinchBench (91.9 vs 93.3 for Opus-4.6) and leads all tested models on τ²-bench Airline (88.0). This is a remarkable result for a fully open model that costs $0.90 per million output tokens — roughly 28 times cheaper than Opus-4.6.
Trinity’s weak spots are instruction-following benchmarks (IFBench, 52.3) and scientific reasoning (GPQA-Diamond, 76.3), where it notably trails competitors. SWE-bench (63.2) is also below most competitors — something Arcee openly acknowledges: becoming the world’s best coding model was not the stated priority.
Pricing and availability
Inference via Arcee’s API costs $0.90 per million output tokens. For comparison, the closest competitor on agentic tasks, Claude Opus-4.6, costs $25 per million output tokens — meaning Trinity is roughly 28 times cheaper at comparable quality on agentic benchmarks. For tasks where the model generates long reasoning chains and calls tools many times per session, this difference is significant: a typical session of 100,000 output tokens will cost $0.09 on Trinity versus $2.50 on Opus.
Trinity-Large-Thinking is available through several platforms: Arcee API, OpenRouter, and DigitalOcean Agentic Inference Cloud. BF16 weights are published on Hugging Face, with quantized variants also available in FP8 and W4A16 (INT4 weights with 16-bit activations). Deployment is supported via vLLM starting from version 0.11.1, as well as the Hugging Face Transformers library with trust_remote_code=True.
Conclusion
Trinity-Large-Thinking is currently the most powerful fully open reasoning model built outside China. Chinese labs, which previously set the pace in the open-weight race, have been shifting toward closed products: in the last week of March 2026 alone, Alibaba released three closed models in a row — no weights, API only. The flagship Qwen3.5-Omni is now available exclusively as a cloud service, even though the openness of earlier Qwen releases attracted over 290,000 developers and spawned more than 113,000 derivative models. Against this backdrop, Arcee’s bet on fully open weights looks like a well-timed strategic decision: as the leading suppliers of open models begin to close up, Trinity fills the emerging gap — and does so with a model that on agentic tasks comes very close to the best closed alternatives.







