
Image generation has become popular from past couple of years. The image generation technique has become popular in various applications. Many computer vision tasks, including image inpainting, image style transfer, colorization, etc. can be considered as image translation.
Image translation can be defined as follows. Given an image XS, we map it to a target domain image XT that shares some similarity or has a close relationship with XS. Given a paired dataset, early approaches learn the mapping by using the input-output pairs in a supervised manner. The main challenge is to learn and generalize the relationship between the given pairs. However, paired data sets are usually hard to collect, and the corresponding target domain image may not even exist in practice. For example, it is hard to connect the set of paired images between photos and artistic works. Another example: if the two domains are male faces and female faces, then there does not exist paired data of the same person. In these cases, supervised models fail because of the lack of a ground truth mapping for training.
The main task is to generate many images from one single image. Given two image domains A and B, the task is to learn to transfer images in domain A to domain B, and vice versa. For example, in the edge-to-shoe translation task, there can be different colors and textures when generating shoes. In this work, researchers show results on generating shoes and handbags with diverse colors and textures given the edge images. Besides, when the additional variable is kept the same for different edge inputs, it can generate objects with the same colors.
Generative Adversarial Networks
The generative adversarial network (GAN) is a powerful generative model that can generate plausible images. The GAN contains two modules: a generator G that generates samples and a discriminator D that tries to distinguish whether the sample is from the real or generated distribution. The generator aims to confuse the discriminator by generating samples that are difficult to differentiate from the real ones. GAN is a powerful tool to match the generated image to the real image distributions, especially when paired images are not available.
Unsupervised Image-to-Image Translation
Taigman introduced the domain transfer network (DTN) to generate emoji-style images from facial images in an unsupervised manner. In the DTN, image translation is a one-way mapping. If we train another model to map the emoji images back to real faces, the face identity may be changed. More recently, bidirectional mapping becomes more appealing, and has been studied in the DiscoGAN, CycleGAN and DualGAN. These models use one generator and one discriminator for each mapping, and the symmetric structure helps to learn the bidirectional mapping.
State-of-the-Art Model
Let A and B be two image domains. In supervised image to-image translation, a sample pair (A, B) is drawn from the joint distribution PA, B. The proposed state of the art XOGAN model contains three generators GA, GB and GZ (with parameters θGA, θGB and θGZ, respectively). The additional variable Z is used to model the variation when translating from domain A to domain B. Given a sample A drawn from PA and Z from the prior distribution PZ, a fake sample B¯ in domain B is generated by GB as:
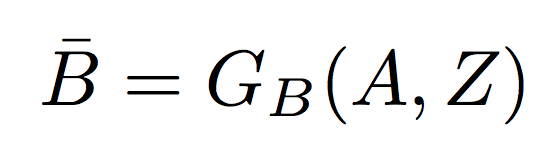
Given B(bar), generator GA generates a reconstruction A(c ap) of A in domain A, and generator GZ encodes a reconstruction Z(cap) of Z
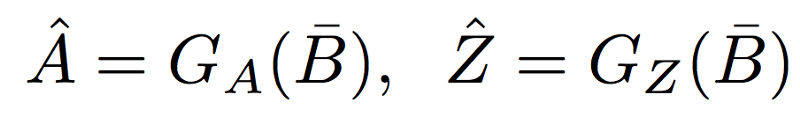
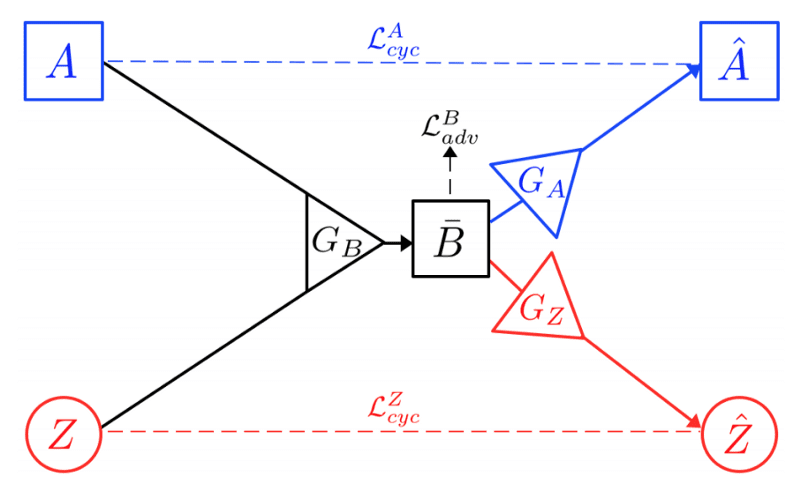
Together, this forms the X-path in Figure 1. To ensure cycle consistency, the generated sample B¯ should contain sufficient information to reconstruct A (for the path A → B¯ → Aˆ), and similarly Zˆ should be similar to Z (for the path Z → B¯ → Zˆ).
On the other hand, given a sample B in domain B, generator GA can use it to generate a fake sample A¯ = GA(B) in domain A; and generator GZ can use it to encode a fake Z¯ = GZ(B). Using both A¯ and Z¯, generator GB can recover a reconstruction of B as Bˆ = GB (A, ¯ Z¯). This forms the O-path in Figure 2.
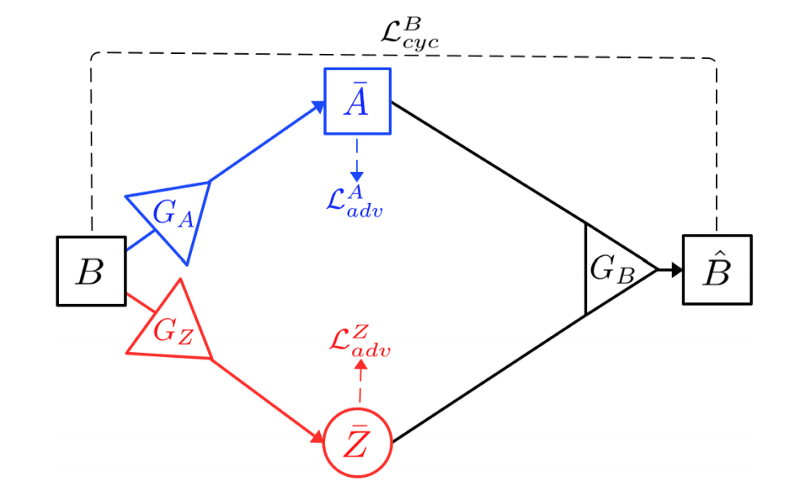
Again, for cycle consistency, Bˆ should be close to B.
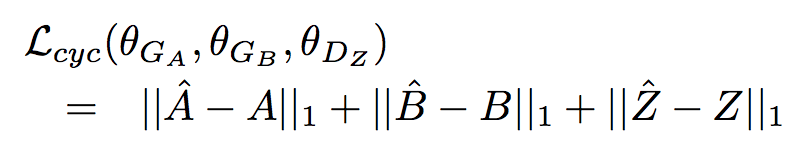
GAN, which is known to be able to learn good generative models, can also be regarded as performing distribution matching. In the following, with the use of the adversarial loss, we will try to match the generated distributions PGA, PGB and PGZ with the corresponding PA, PB and PZ. The three discriminators DA, DB and DZ (with parameters θDA, θDB and θDZ respectively) that are used to discriminate the generated A¯, B¯, Z¯ from the true A, B, Z. The discriminators are binary classifiers, and the discriminator losses are:
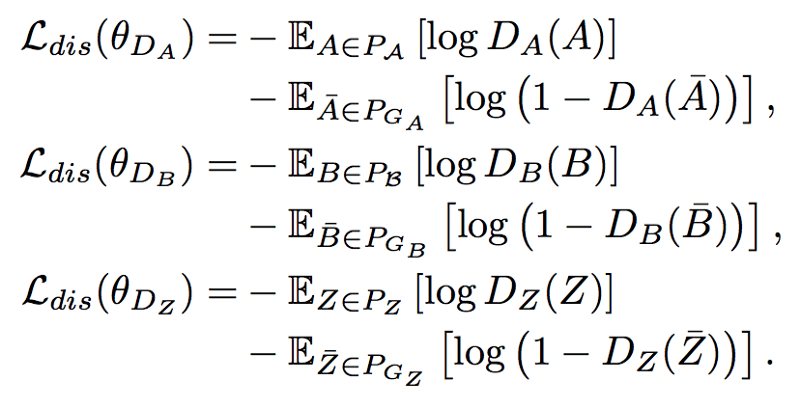
In GAN, the generators, besides trying to minimize the cycle consistency loss, also need to confuse their corresponding discriminators. The adversarial losses for the generators are:
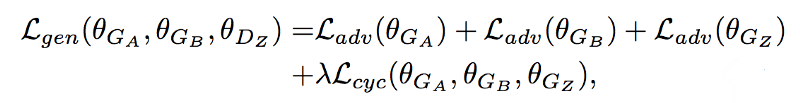
To ensure both cycle consistency and distribution matching, the total loss for the generators is a combination of the cycle consistency loss and the adversarial losses:
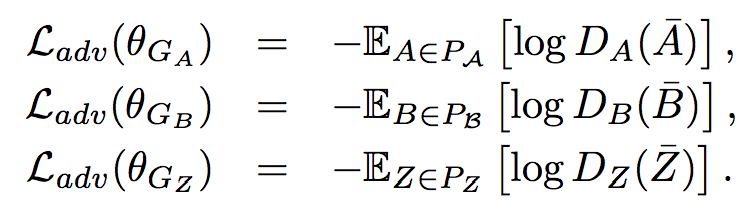
Results
The presented method is a generative model called XOGAN for unsupervised image-to-image translation with additional variations in the one-to-many translation setting. This approach can generate plausible images in both domains, and the generated samples are more diverse than the baseline models. Not only does the additional variable Z learn lead to more diverse results, it also controls the colors in certain parts of the generated images. Experiments on CelebA, edges2shoes and edges2handbags data sets showed that the learned variable Z is meaningful when generating images in domain B.








