Тема генерации изображений становится всё популярнее в последние несколько лет. Многие задачи компьютерного зрения, включая восстановление изображений (image inpainting), передачу стиля изображения (style transfer), раскраску (colorization), можно рассматривать как преобразование изображений (image translation).
Преобразование изображений может быть определено следующим образом. Пусть дано изображение XS, мы отображаем его в изображение из целевого домена XT, которое имеет некоторое сходство или тесную связь с XS. Таким образом мы можем получить набор данных, составленный из пар (XS, XT). Ранние подходы обучались с помощью алгоритма, который отображал пространство XS в пространство XT, используя XT как метки, то есть с учителем. Главная задача состоит в том, чтобы изучить и обобщить связи между этими парами. Однако такие пары обычно трудно собрать, и соответствующий образ целевого домена может даже не существовать на практике. Например, если два домена являются мужскими и женскими лицами, то парных данных одного и того же человека не существует. В этих случаях модели, обучаемые с учителем, терпят неудачу из-за отсутствия истинных данных для обучения.
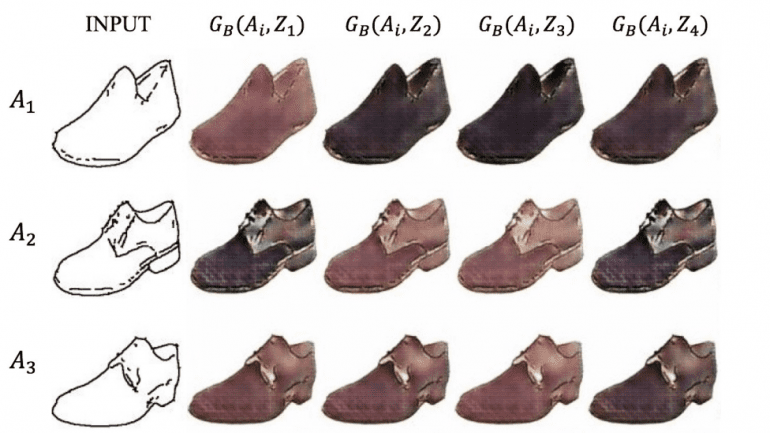
Главная задача исследования — научиться генерировать несколько различных изображений из одного входного. Пусть даны два изображения целевых областей A и B, задача состоит в том, чтобы научиться отображать изображения из области А в область В, и наоборот. На примере с ботинками, могут быть использованы различные цвета и материалы. В своей работе исследователи продемонстрировали результаты на примере генерации ботинок и сумок с отличными от начального изображения цветами и материалами. Кроме того, если дополнительная переменная одинакова для разных входных изображений, она может генерировать объекты с одинаковыми цветами.
Преобразование изображений без учителя
Taigman ввел сеть передачи домена (DTN), чтобы генерировать изображение лица в стиле эмоджи без учителя. В сети передачи домена преобразование изображения является односторонним. Если мы создадим другую модель, которая отображает эмоджи обратно в реальные лица, то лицо будет сильно искажено. Совсем недавно двунаправленное отображение было улучшено и использовано в DiscoGAN, CycleGAN и DualGAN. Эти модели используют один генератор и один дискриминатор для каждого отображения, а симметричная структура помогает изучить двунаправленное отображение.
State-of-the-art модель
Пусть A и B — два домена изображений. При преобразовании изображений с учителем, генерируется пара (A, B) из совместного распределения p(A, B). Предлагаемая современная модель XOGAN содержит три генератора GA, GB и GZ с параметрами θGA, θGB и θGZ соответственно. Дополнительная переменная Z используется для моделирования вариации, когда изображение переводится из домена A в домен B. Пусть дан экземпляр A, полученный из распределения P(A) и переменная Z из априорного распределения P(Z). Тогда ложный экземпляр B¯ в домене G будет сгенерирован как
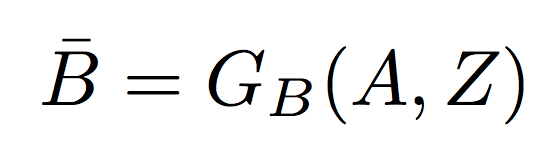
По данному B¯ генератор GA генерирует реконструкцию Aˆ истиной A из домена A, и генератор GZ воссоздает реконструкцию Zˆ истиной Z.
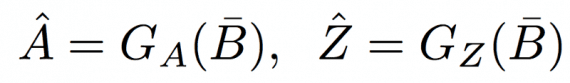
Вместе это образует X-путь, который изображен на Рисунке 1. Чтобы обеспечить согласованность циклов, сгенерированный образец B¯ должен содержать достаточно информации для восстановления A (по пути A → B¯ → Aˆ), и аналогично Zˆдолжен быть похож на Z (по пути Z → B¯ → Zˆ).
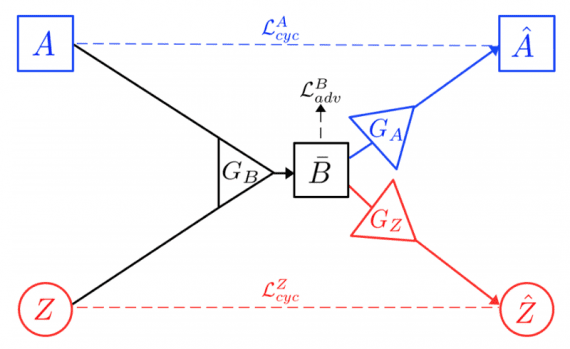
С другой стороны, учитывая экземпляр B из домена B, генератор GA может использовать его для генерации ложного образца A¯ = GA (B) в домене A, и генератор GZ может использовать его для генерации подделки Z¯ = GZ (B). Используя как A¯, так и Z¯, генератор GB может восстановить реконструкцию B, как Bˆ = GB (A¯, Z¯). Это схематично изображено на O-пути на Рисунке 2.
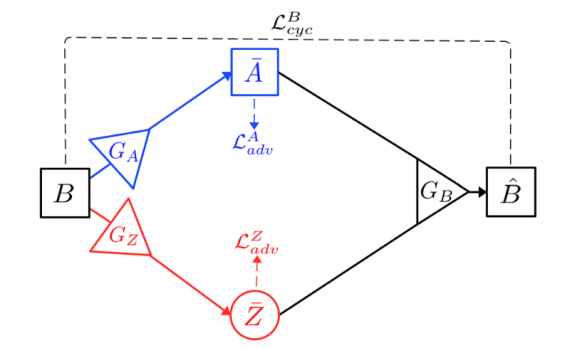
Снова, для согласованности пути, Bˆ должен быть близок к B.
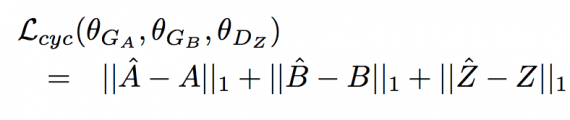
GAN, который, как известно, способен выучить хорошие генеративные модели, также может быть использован для сопоставления распределений. В дальнейшем с использованием состязательной функции потерь, мы попытаемся сопоставить генерируемые распределения PGA, PGB и PGZ с соответствующими истинными PA, PB и PZ. В модели используется три дискриминатора DA, DB и DZ с параметрами θDA, θDB и θDZ соответственно, которые используются для распознавания сгенерированных A¯, B¯, Z¯ из истинных A, B, Z. Дискриминаторы являются двоичными классификаторами, а их функция потерь задается в следующим образом:
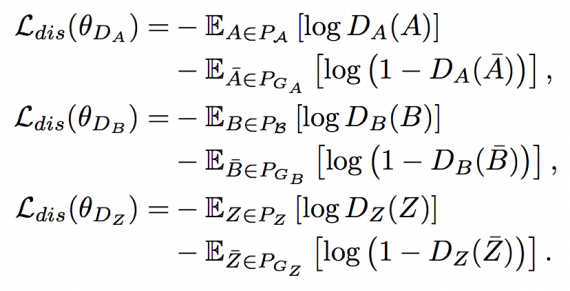
Данные генераторы помимо попытки минимизировать функцию потерь последовательности циклов, также должны пытаться обмануть соответствующие дискриминаторы. Состязательные функции потерь генераторов задаются следующим образом:
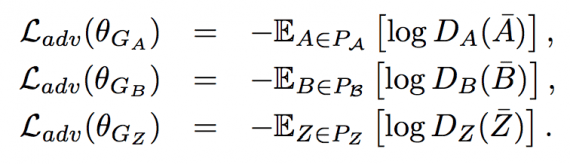
Для обеспечения согласованности циклов и соответствия распределений, общая функция потерь для генераторов представляет собой комбинацию функции потери последовательности циклов и состязательных функций потерь:
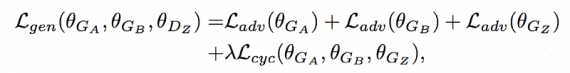
Представленный метод представляет собой генеративную модель под названием XOGAN для преобразования без учителя в изображение с дополнительными вариациями по типу «один во многие». Такой подход может генерировать правдоподобные изображения в обоих доменах, а сгенерированные образцы более разнообразны, чем у базовых моделей. Мало того, что дополнительная переменная Z может привести к более разнообразным результатам, она также контролирует цвета в определенных частях сгенерированных изображений. Эксперименты на наборах данных CelebA, edge2shoes и edge2handbags показали, что изученная переменная Z значима при создании изображений в домене B.


Перевел Александр Сахнов