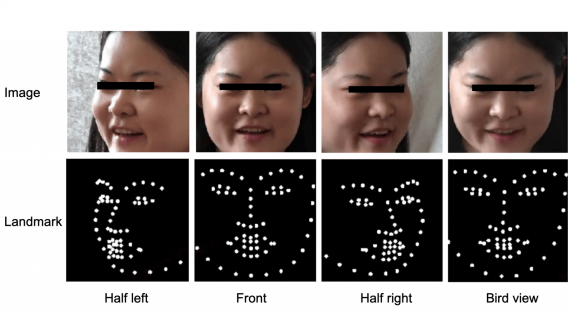
Распознавание выражений лица, или эмоций — интересная и сложная задача из области компьютерного зрения. В будущем распознавание лиц будет выполняться автоматически с помощью алгоритмов, а исследователи будут извлекать реальную выгоду. Возможности применения обширны — запись видео, рекомендации по фильмам или рекламе, обнаружение боли в телемедицине и т.д.
Тем не менее, даже не все люди хорошо справляются с распознаванием чужих эмоций, как же тогда компьютеры справляются с этим? Известно, что люди выражают эмоции с помощью глаз, бровей и движений губ. Насколько хороши современные подходы к распознаванию эмоций? Современные алгоритмы машинного обучения демонстрируют точность в 55% для распознавания выражения лиц на изображениях и точность в 46% для распознавания лиц на видео.
Давайте теперь узнаем, как ковариации повышают точность, с которой распознается и классифицируется выражение лица.

Группа исследователей из ETH Zurich (Швейцария) и KU Leuven (Бельгия) указывают на то, что классификация выражений лица по категориям (грусть, гнев, радость и т.д) требует захвата точек, определяющих искажение черт лица. Исследователи считают, что для этого лучше всего подходит ковариация.
Подход был применен к двум отдельным задачам:
- Распознавание эмоций на изображении: после сверточных слоев вводится covariance pooling. Размерность уменьшили с использованием концепций из manifold network, которая обучалась вместе со сверточной нейросетью.
- Распознавание эмоций на видео: covariance pooling использовалось для фиксации эволюции характеристик каждого кадра во времени. Исследователи провели эксперименты с manifold networks для объединения кадровых характеристик.
Углубимся в подход распознавания лиц с использованием covariance pooling.
Архитектура модели
Начнем с изображений. Алгоритм начинается с обнаружения лиц: нужно избавиться от нерелевантной информации. Распознавание лица выполняется по расположению основных точек, затем лицо выравнивается. После этого нормализованные данные подаются в CNN. Для объединения координат объекта из CNN используется covariance pooling. Наконец, manifold network используется для изучения вторичных принаков.
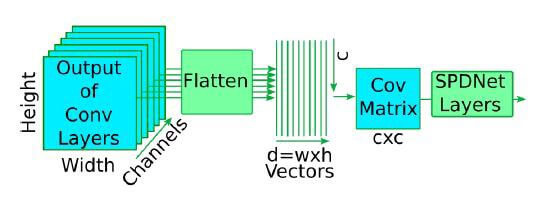
Модель распознавания лиц на видео похожа на распознавание лиц на изображениях, но имеет свои особенности. Во-первых, она начинается с получения необходимой информации из видео: сначала извлекаются кадры, а затем распознаются лица и выполняется корректировка для каждого отдельного кадра. Кроме того, авторы этой модели предлагают объединять кадры с течением времени, поскольку временная ковариация захватывает необходимую динамику движения лица. Впоследствии снова используется manifold network для уменьшения размерности и нелинейности в ковариационных матрицах.
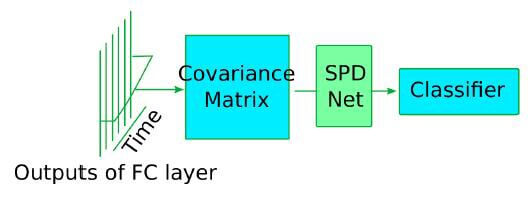
Теперь давайте кратко рассмотрим как использовались covariance pooling и manifold network для изучения второстепенных признаков.
Covariance pooling
Ковариационная матрица использовалась для суммирования второстепенной информации в единое множество. Чтобы сохранить геометрию при использовании слоев симметричной положительно определенной (SPD) manifold network, ковариационные матрицы должны быть SPD. Но, даже если матрицы только положительно полуопределены, их можно нормализовать, добавив кратное следа к диагональным элементам ковариационной матрицы.
SPD Manifold Network (SPDNet)
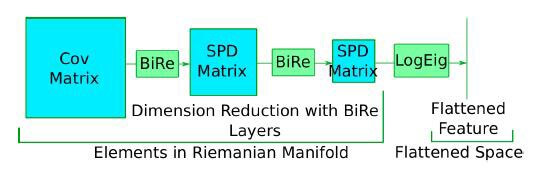
Ковариационные матрицы, рассчитанные на предыдущем этапе, обычно принадлежат Риманову многообразию SPD матриц. Они очень большие, их размерность необходимо уменьшить без потери геометрической структуры. Кратко рассмотрим конкретные шаги для решения этой задачи:
* Bilinear Mapping Layer (BiMap) выполняет задачу уменьшения размерности при сохранении геометрической структуры.
* Eigenvalue Rectification Layer (ReEig) используется для введения нелинейности.
* Log Eigenvalue Layer (LogEig) наделяет элементы в Римановом многообразии так, что матрицы выравниваются, и применяются стандартные Евклидовы операции.
Обратите внимание, что слои BiMap и ReEig используются вместе, поэтому эти два слоя кратко называются BiRe.
Результаты в распознавании эмоций на изображении
Чтобы сравнить эффективность предлагаемого подхода с некоторыми базовыми моделями, исследователи использовали два набора данных:
- Real Affair Faces (RAF) содержит 15331 изображений с семью основными категориями эмоций, из которых 3068 использовались для проверки и 12271 для обучения.
- Статические выражения лица в естественных условиях (SFEW) 2.0 содержит 1394 изображения, из которых 958 использовались для обучения и 436 для проверки.
Затем было решено экспериментировать с различными моделями, используя covariance pooling. В подробностях модели рассмотрены в таблице 1.
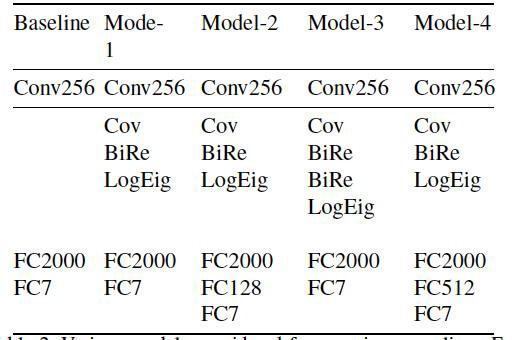
Точность моделей, описанные в таблице выше, а также некоторых других state-of-the-art моделей без ковариационного объединения представлена в таблице 2.
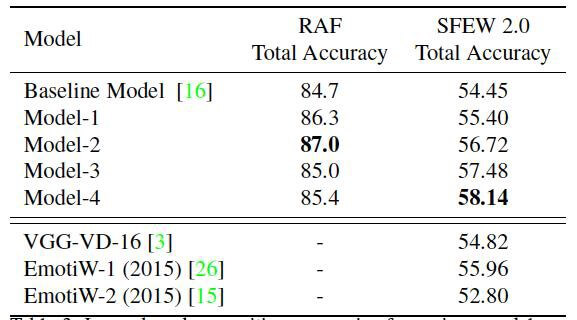
Как видите, модель-2 демонстрирует точность 87% с набором данных RAF и превосходит базовую модель на 2,3%, что является очень хорошим результатом для такой сложной задачи, как распознавание лиц. Model-4 с covariance pooling показывает улучшение почти на 3,7%по сравнению с базовым уровнем в наборе данных SFEW 2.0, что, очевидно, оправдывает использование SPDNet для распознавания эмоций на изображениях. В целом, эти результаты являются наилучшими результатами для такого рода задач.
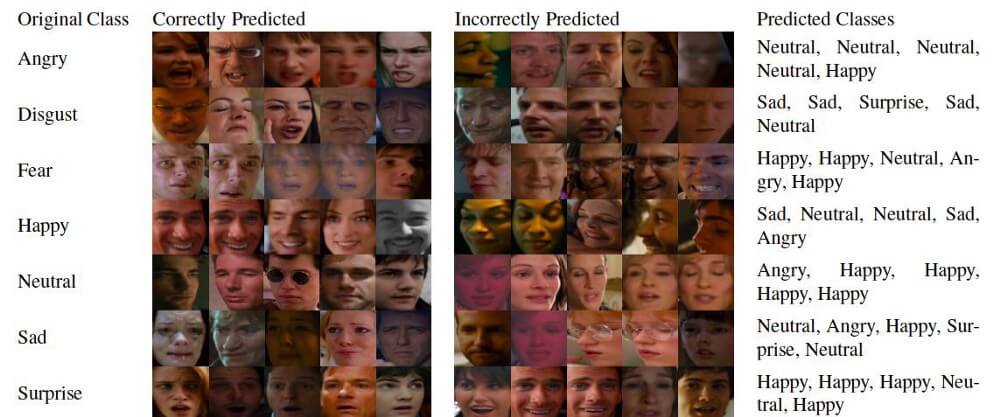
Результаты распознавания лиц на видео
Для этой задачи использовался набор данных Acted Facial Equions in the Wild (AFEW). Этот набор данных был подготовлен путем нарезки видеороликов из фильмов. Он содержит около 1156 общедоступных видео роликов, из которых 773 были использованы для обучения и 383 для проверки.
Точность результатов предложенных методов с covariance pooling, а также некоторых других современных методов, выбранных для сравнения, приведены ниже. Датасеты, используемые для предобучения других моделей неоднородны, поэтому подробное сравнение требует дальнейших исследований.
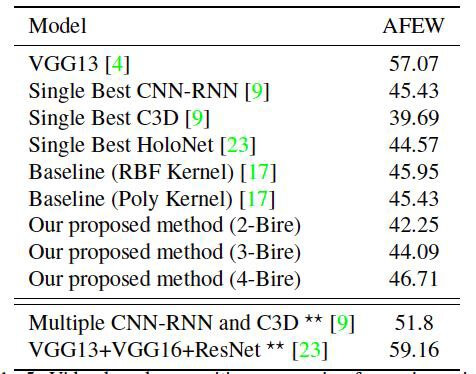
Как видно из таблицы 3, модель с covariance pooling и четырьмя слоями BiRe смогла превзойти результаты базовой модели. Она также продемонстрировала более высокую точность, чем все другие модели, прошедшие обучение на общедоступных наборах данных. Сеть VGG13, которая показывает гораздо более высокую точность, была обучена на частном наборе данных, содержащий значительно большее количество образцов. Тем не менее, мы не можем заключить, что использование covariance pooling в задаче распознавания выражений лиц на видео дает улучшение точности распознавания.
В сухом остатке
Исследователям удалось достичь лучших на сегодня результатов в задаче распознавания эмоций на изображениях. Точность распознавания после введения covariance pooling в модель превосходила все другие существующие методы.
Результат распознавания эмоций на видео улучшить не удалось. Не очень высокая точность предлагаемого метода может быть результатом относительно небольшого размера набора данных AFEW по сравнению с параметрами в сети. Авторы делают вывод о том, что необходима дальнейшая работа для того, чтобы увидеть, может ли совместное обучение с использованием сверточной сети и SPDNet улучшить результаты.
Перевел — Руслан Хабиббулин, оригинал — Kateryna Koidan