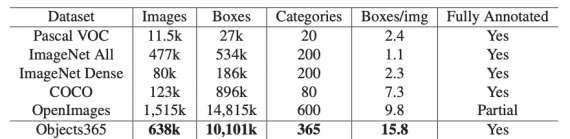
Objects365 — это самый крупный размеченный датасет для распознавания объектов. Данные состоят из 638 тысяч изображений, 365 категорий объектов и 10 миллионов размеченных границ объектов. Датасет и предобученные нейросети доступны по ссылке.
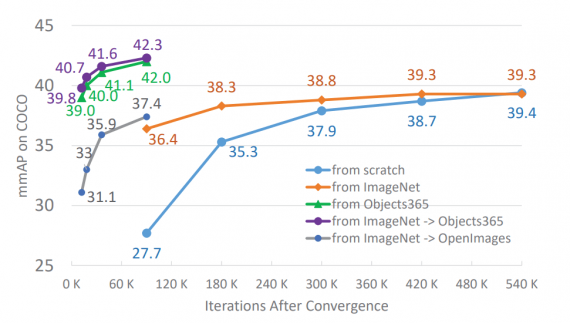
Разметка объектов проводилась вручную с помощью трехступенчатого пайплайна. Предобучение моделей на данных Objects365 повышает их качество на задачах, которые связаны с локализацией объектов. Предобученные на Objects365 нейросети обходят те, что обучались на ImageNet, на 5.6 пунктов по точности (mmAP). Тесты проводились на датасете COCO с фиксированным количеством итераций обучения модели. При увеличении количества итераций Objects365 все равно обходит ImageNet как датасет для предобучения. При этом время на регулирование модели (finetuning) сокращается до 10 раз без потери в точности.
Сбор данных
Чтобы обеспечить разнообразие изображений, исследователи собрали их из Flicker. Все изображения в датасете могут легально использовать для исследовательских целей. На основе собранных изображений исследователи отобрали 11 общих категорий: люди, гостиная, одежда, кухня, инструмент, транспорт, ванная, электроника, овощи, офисные принадлежности и животные. Из этих крупных категорий были сформированы 442 более детальных класса объектов. В финальную выборку попали 365 наиболее частых классов из 442. Категории в Objects365 содержат классы объектов из PASCAL VOC и COCO.
Процесс аннотирования данных состояла из трех шагов:
- Бинарная классификация: содержит ли изображение хотя бы один объект из 11 общих категорий объектов. Если да, то изображение проходило на следующий шаг;
- Каждой изображение размечали тегами из 11 общих категорий. У одного изображения могло быть несколько тегов;
- Один аннотатор размечал объекты на изображениях только одной общей категории