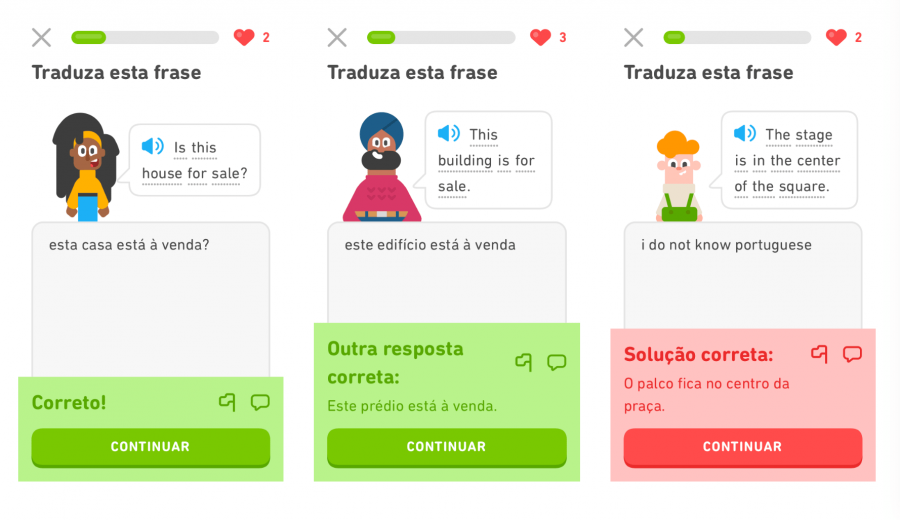
Duolingo анонсировали соревнование по машинному переводу STAPLE. На текущий момент большинство систем по машинному переводу выдают один перевод входной последовательности. В Duolingo пользователь обучается языку с помощью упражнений по переводу. В связи с этим генерация нескольких эквивалентных переводов одной фразы может оптимизировать процесс проверки заданий. STAPLE комбинирует две задачи: машинный перевод и перифраз предсказанного перевода. Тренировочный набор данных опубликуют 13 января 2020 года.
Данные
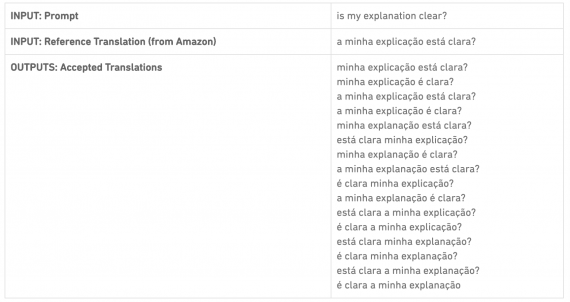
Датасет состоит из пар фраз на английском языке и их перевода на один из 5 других языков. Для каждой пары в датасете есть размеченный список эквивалентных переводов. Задача заключается в том, чтобы выдать список эквивалентных переводов. Целевые списки с эквивалентными переводами собирали вручную и проранжированы по степени схожести с начальным переводом.
Языки, на которых представлены переводы, включают в себя португальский, венгерский, японский, корейский и вьетнамский.
Метрика
Основной метрикой для оценки моделей выбрали взвешенный макро F1. Модели оцениваются на основе того, как сильно сгенерированный список переводов перекликается с целевым списком. При этом переводы из целевого списка с более высокой вероятностью имеют больший вклад в метрику, чем переводы с низкой вероятностью.
Подробнее о сроках проведения соревнования и метрике можно узнать по ссылке.




