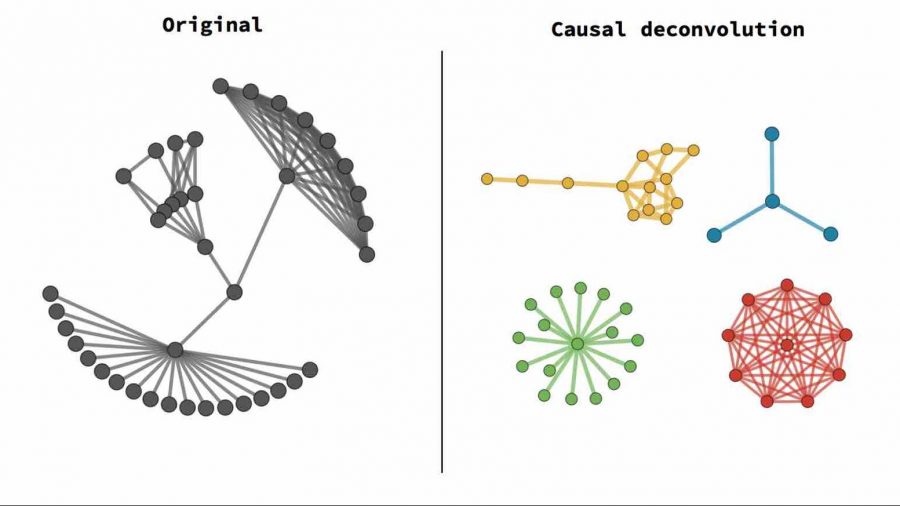
Одна из фундаментальных задач в машинном обучении — поиск и расшифровка причинно-следственных связей в больших массивах данных. Исследование, проведенное учеными KAUST, предлагает новый подход к решению проблемы иерархического структурирования данных и индуктивного вывода.
Проблема причинности
Современный искусственный интеллект не способен принимать решения на основе обнаруженных причинно-следственных связей. Пока что алгоритмы умеют выявлять только закономерности в данных, которые обрабатывают. Чем больше данных обработает ИИ — тем точнее будет результат.
Например, языковая модель GPT-2 от разработчиков OpenAI обучилась генерации текста, обобщению и переводу просто анализируя огромное количество данных. Алгоритм работает используя индуктивный научный метод — выдает нужный результат, сопоставляя множество факторов. Для перевода слова перебираются все варианты, где оно встречается. То слово, которое наиболее часто встречается в похожем контексте, выбирается как результат.
При этом модель не способна делать выводы и решать проблемы на основе уже полученного опыта — для каждой новой задачи ей нужно учиться заново.
Метод «причинной развертки»
Исследователи KAUST описали подход, который позволит обойти вышеописанные проблемы. Работа «Causal deconvolution by algorithmic generative models», опубликованная в журнале Nature, описывает алгоритмическую генеративную модель, которая способна более глубоко понимать причинные механизмы, обучаясь без учителя.
Метод использует сочетание подходов математической концепции алгоритмической теории информации и исчисление причинности Дж. Пёрла для создания механизма логического вывода. Основное отличие от предыдущих подходов — переход от взгляда наблюдателя к объективному анализу явлений, основываясь на отклонениях от беспорядочности.
«Наш подход использует основанное на отклонениях каузальное вычисление, чтобы вывести представления модели» — пишут исследователи.
Получается, что логика — это отклонение от беспорядочности. Находя такие отклонения в большом массиве данных, алгоритм находит причинно-следственные связи между объектами отклонения, и затем может использовать это для оптимального решения задачи.
Подход позволит алгоритмам лучше справляться с абстрактными умозаключениями и пониманием причин и сможет дополнить статистические методы, улучшая модели, основанные на глубоком обучении.



