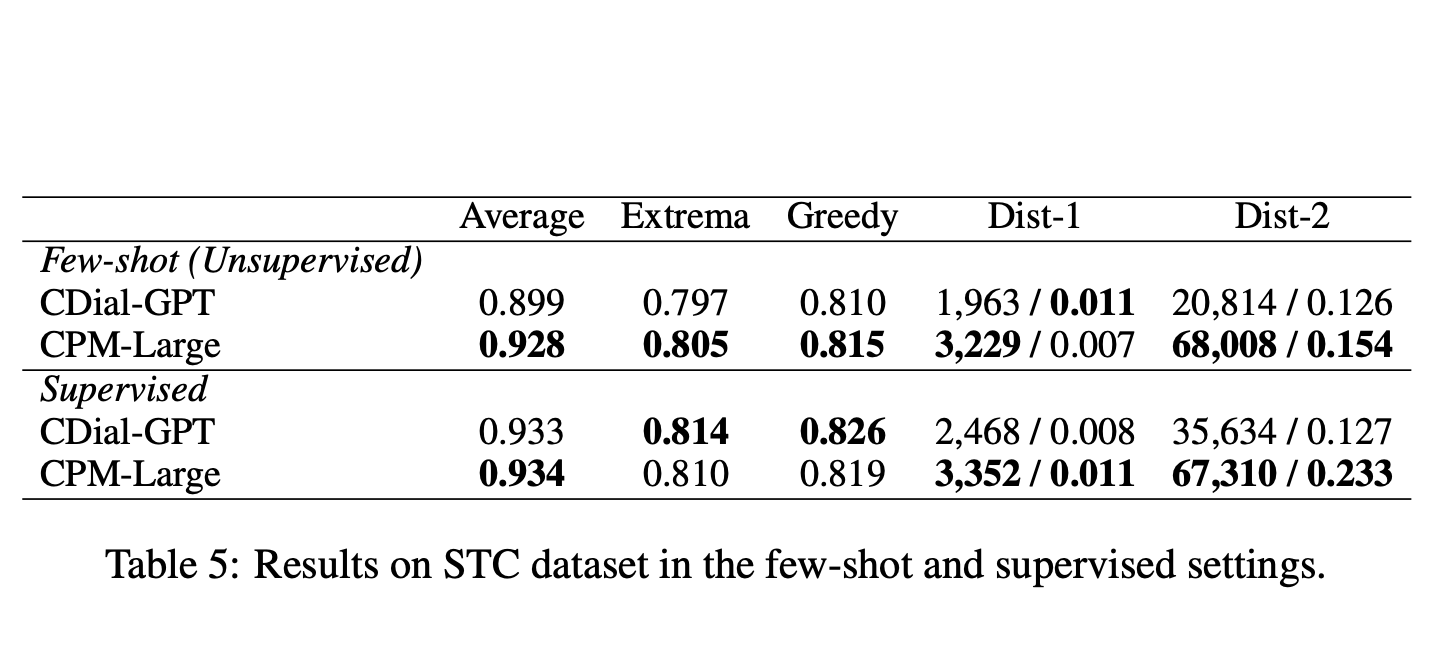
CPM — это предобученная языковая модель для китайского языка. Модель имеет 2.6 миллиарда параметров и обучалась на 100 гигабайтах текстов на китайском. CPM позволит улучшить качество результатов для таких задач, как генерация эссе, CLOZE, диалоговая система и понимания языка. Разработчики опубликовали код и параметры модели в открытом репозитории на GitHub.
В чём проблема state-of-the-art NLP моделей
Предобученные языковые модели показали себя эффективными для задач обработки естественного языка. Модель GPT-3 с 175 миллиардами параметров и 570 гигабайтами данных для обучения привлекала внимание своей возможностью дообучаться в формате на нескольких примерах (zero-shot обучение). Однако использование GPT-3 для решения NLP задач на китайском языке является проблематичным из-за того, что обучающий корпус текстов у GPT-3 — на английском языке. Кроме того, параметры модели недоступны публично.
Подробнее про CPM
Chinese Pretrained Language Model (CPM) — это генеративная языковая модель, предобученная на большом наборе данных текстов на китайском языке. Исследователи заявляют, что это самая большая предобученная модель для китайского языка. CPM заимствует архитектуру у GPT модели.

