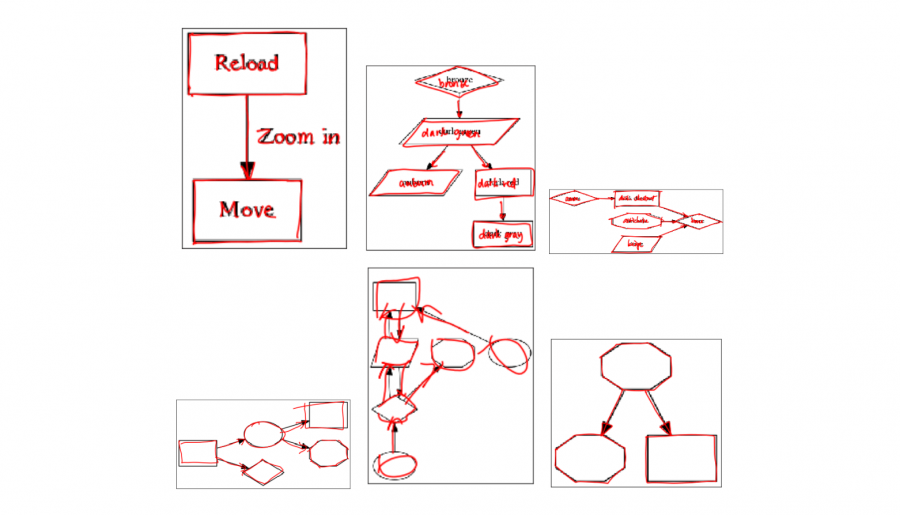
DIDI — это датасет, который содержит изображения нарисованных диаграмм и данные о процессе отрисовки диаграмм. Всего в датасете 58,655 рисунков, которые нарисовали 364 добровольцев. Сбором датасета занимались исследователи из Google Research и ETH Zurich. Исследователи собрали DIDI, чтобы спровоцировать исследовании в области представления интерактивных графических символов.
Описание проблемы
Рукописный текст и скетчи являются одним из основных способов хранения информации. Распознавание символов (OCR) — это ранний подход к конвертации рукописного текста в цифровое представление. Электронные чернила позволяют комбинировать гибкость и эстетичность рукописного текста с возможностью обрабатывать и редактировать данные интерактивно. Существующие работы фокусировались на отдельном представлении рукописного и нарисованного контента. Исследователи предлагают обучать представления для такого вида хранения информации совместно. Для этой задачи они опубликовали датасет DIDI.
На данный момент существует три датасета с рукописными рисунками:
- Данные нарисованных диаграмм от Czech Technical University;
- KONDATE от Tokyo University of Agriculture and Technology;
- Датасет с 419 флоучартами от University of Nantes
Что внутри датасета
DIDI состоит из двух частей:
- 22,287 диаграмм с текстовыми подписями;
- 36,368 диаграмм без текстовых подписей
Данные собирали с помощью 384 добровольцев. Исследователи попросили добровольцев перерисовать существующие диаграммы в специальном мобильном приложении на планшете с помощью стилуса. Общее количество рисунков одного добровольца варьируется от 1 до 1291.
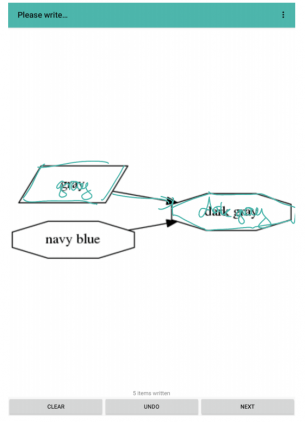
Формат данных
Сами данные представляются в формате NDJSON. Один элемент датасета содержит следующую информацию:
- Ключ, который является уникальным идентификатором рисунка;
- Идентификатор лейбла, который содержит sha1 хэш dot файла, который использовали для генерации изображения;
- Изображение в формате листа с штрихами. Каждый штрих является листом с значениями x, y координат и временной отметкой
