
HiPlot — это библиотека для интерактивной визуализации многомерных данных. HiPlot использует параллельные графики и другие графические методы представления информации. Работать с библиотекой можно напрямую из Jupyter ноутбуков. Инструмент создавался для того, чтобы помочь делать эксплораторный анализ на многомерных данных. Разработкой библиотеки занимались исследователи из FAIR. Установить библиотеку можно с помощью pip: pip install hiplot.
Библиотека позволяет ML исследователям оценить влияние гиперпараметров на скор моделей. Параллельные графики — это способ визуализации и фильтрации многомерных данных. Рассмотрим пример, когда запущен процесс обучения модели. На каждой итерации получаются два скалярных параметра: дропаут и learning rate, — и один алгоритм оптимизации. Из этих данных рассчитывается функция потерь, которая также является скалярной величиной. Каждую итерацию можно представить в виде объекта данных с параметрами (dropout, lr, optimizer, loss). HiPlot рисует одну вертикальную ось для каждого параметра. Итерации представляются как непрерывные линии, которые проходят через оси параметров.
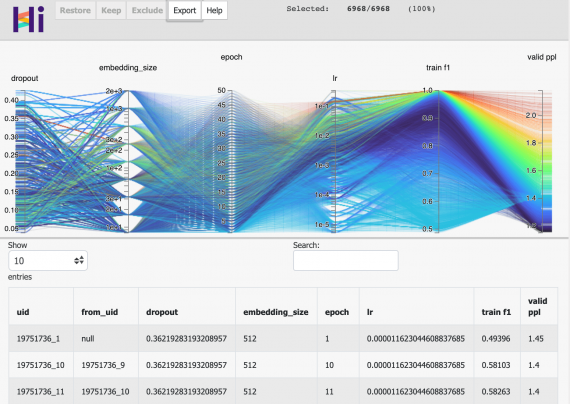
Подробнее про функционал библиотеки
HiPlot обладает следующими характеристиками:
- Интерактивность: параллельные графики в библиотеке интерактивны, что смотреть на часть данных на графике без дополнительной фильтрации данных перед визуализацией;
- Доступ к библиотеке через Jupyter ноутбуки и через сервер;
- По дефолту библиотека работает с данными в формате CSV и JSON, однако есть возможность добавить кастомный парсер на Python, чтобы визуализировать данные в специфичном формате;
- Визуализация подходов к тюнингу гиперпараметров моделей, как Population-Based Training
