Исследователи из Baidu предложили нейросетевую модель для задачи распознавания символов на изображении (OCR).
Архитектура подхода
Архитектура PP-OCR основана на легковесных нейросетях, которые были улучшены. Предложенный фреймворк состоит из трёх шагов: детектирование границ текста, исправление угла текста и распознавание текста. Все три модуля используют легковесные базовые сети для ускорения работы. Это позволяет использовать обученные модели в встраиваемых устройствах.
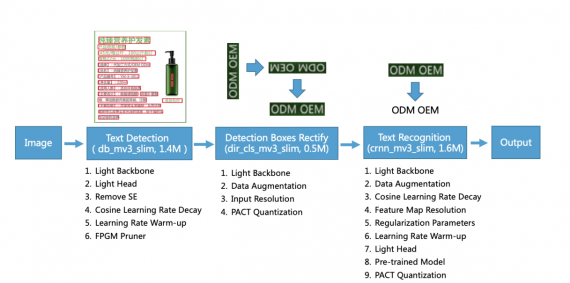
Первый модуль использует детектор текста, который основан на модели сегментации. Цель модели — детектировать и разметить место расположения текста на изображении. На втором этапе к части изображения с текстом применяется геометрическая трансформация, чтобы выровнять текст. На финальном шаге сверточная рекуррентная сеть распознает текст. Исследователи используют квантизацию, learning rate warm-up и прунинг, чтобы оптимизировать размер сети и её работу.
Данные для обучения
Исследователи собрали данные для китайского и английского языков. Всего — три маленьких датасета, которые объединяются в один большой:
- 97 тысяч изображений для детектирования текста на изображении;
- Датасет для классификации направления текста из 600 тысяч изображений;
- 17.9 миллионов изображений для задачи распознавания текста
