Исследователи из Facebook AI разработали универсальную модель, которая играет в шахматы, покер и Go. ReBeL — это вероятностная модель, которая объединяет в себе обучение с подкреплением и поиск при поиске оптимального хода. Модель обходит человека в игре Техассий холдем и выдает сравнимые результаты, играя в шахматы и Go.
Ограничение прошлых моделей
Прошлые нейросетевые модели, которые играли в игры лучше людей, фокусировались обычно на одной игре. Ранее не предлагали универсального фреймворка для игры. Исследователи из FAIR обучили RL-агента играть в игры с полной и неполной информацией.
Подробнее про модель
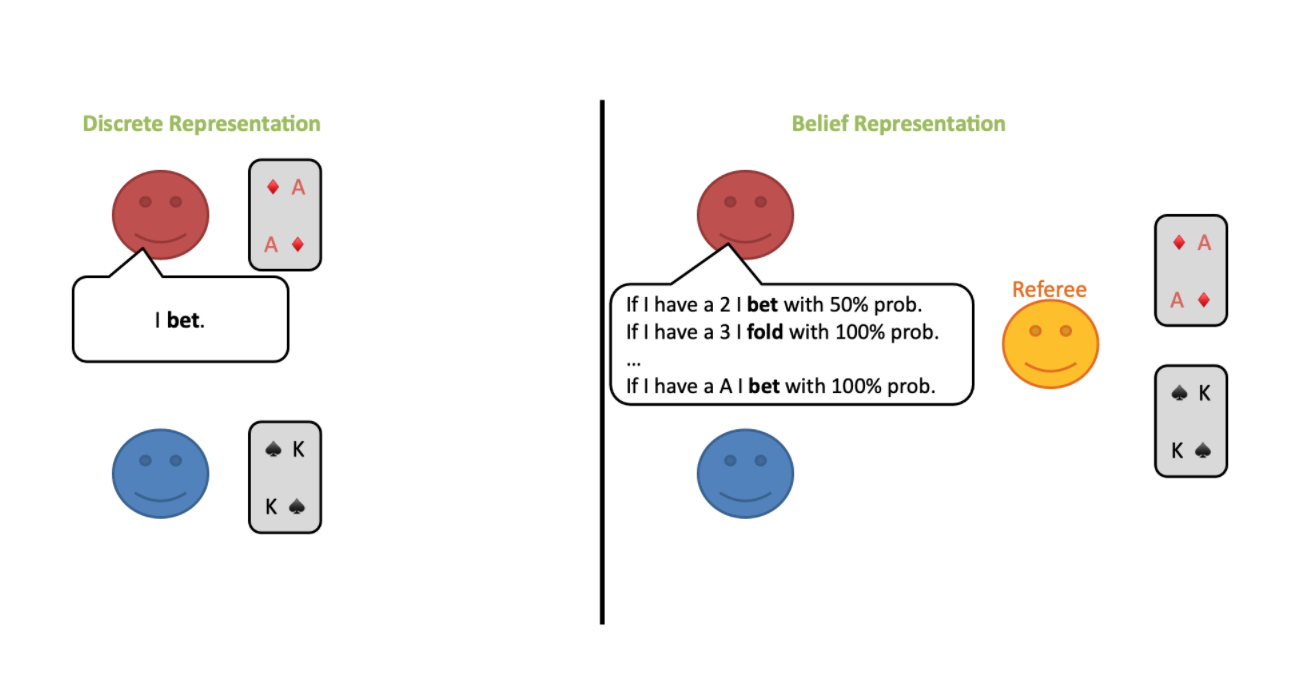
ReBeL — это универсальная вероятностная модель, которая адаптирована под игры с двумя игроками и нулевой суммой (zero-sum games). Она способно принимать рещения и играть с использованием факторизованного распределения вероятностей разных стратегий, которых другие игроки могут придерживаться.
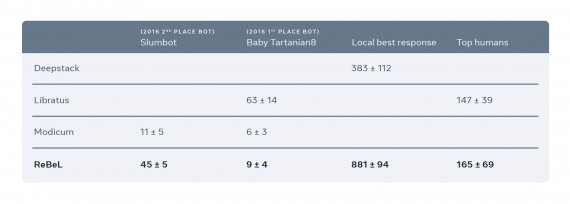
Метод оценивали на двух играх: вариация покера Техасский холдем и Liar’s Dice. Результаты показали, что модель обходит человека в игре в покер. Подробности реализации модели и оценки ее качества доступны в официальном посте.
