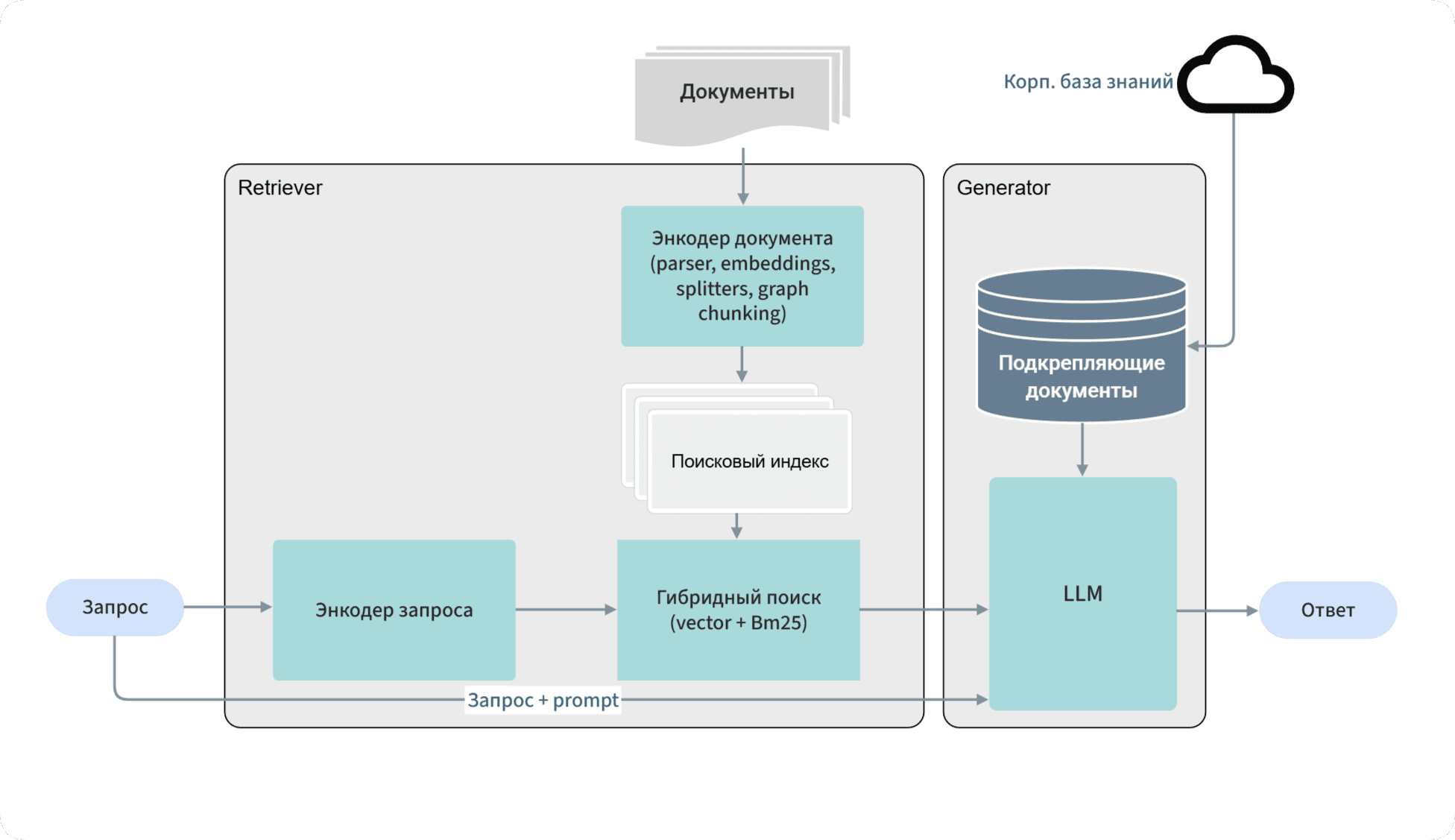
RRNCB (Russian RAG Normative — Corporate Benchmark) — первый российский открытый бенчмарк для комплексной оценки RAG-моделей при работе с нормативной, правовой и технической документацией компаний. RRNCB адаптирован под специфику русскоязычных данных — корпоративных документов, кодексов, ГОСТов и СНИПов, СП, регламентов, финансовых отчетов. В отличие от существующих решений, которые оценивают преимущественно языковые модели, RRNCB проводит комплексную оценку RAG как продукта — от извлечения данных до финальной генерации ответа. Бенчмарк запущен 20 августа 2024 года, первые результаты будут опубликованы 20 сентября. Регистрация RAG решений участников продолжается до 3 сентября. Для участия заполните заявку.
Специализированный датасет
Основой бенчмарка является специализированный датасет, включающий вопросы, эталонные ответы и подтверждающие фрагменты документов. Датасет сбалансирован и охватывает различные домены: техническую документацию, юридические кодексы, текстовые описания и табличные данные.
Структура датасета включает мультимодальные данные:
- Текстовые документы различной сложности;
- Табличные данные с числовыми показателями;
- Комбинированный контент, требующий анализа нескольких источников.
Бенчмарк содержит от 500 до 1000 вопросов для оценки основных метрик и дополнительно 30–50 специализированных мультимодальных заданий. Вопросы имеют различную структуру, включая навигационные («в каком разделе документа говорится о…»), retrieval («Когда был принят ГОСТ ИСО 1940-2-99?»), композиционные («Какие требования предъявляются к возводимым конструкциям…»), и вопросы, требующие дополнительной обработки контекста из нескольких документов.
Комплексные метрики оценки
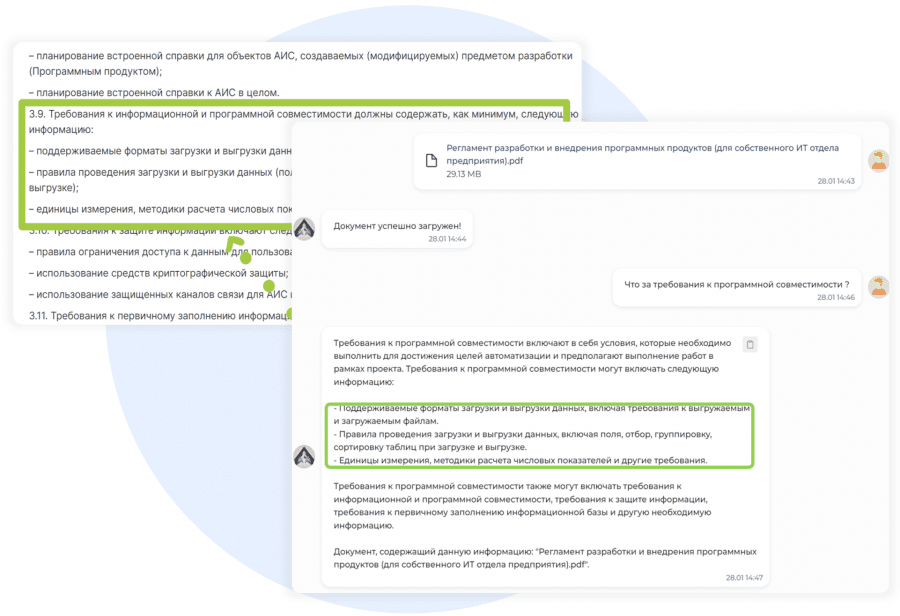
Методология RRNCB включает метрики, разделенные на несколько категорий для объективного анализа качества работы компонентов RAG решений.
End-to-End оценка качества текста использует классические метрики RougeN (N=2, 4) и RougeL для измерения полноты, точности и F1-меры. Эти метрики оценивают лексическое пересечение с эталонным ответом, что позволяет количественно измерить качество генерации.
Сравнительная оценка с помощью LLM-судей. Четыре крупные языковые модели (среди кандидатов — GPT-4, GPT-5, Grok, DeepSeek, Gemini) выступают в роли анонимных судей, сравнивая ответы разных RAG решений. Модели оценивают стилистическое соответствие, релевантность запросу и фактологическую точность. Результат для каждого ответа представляется в виде среднего балла от 0 до 1, где 1 означает единогласную победу в сравнении с конкурентами.
Производительность и функциональность включает измерение скорости ответа — времени в секундах от получения запроса до генерации первого токена. Дополнительно оценивается способность к уточнению — доля случаев, когда RAG корректно задает уточняющие вопросы при неоднозначных запросах, что улучшает финальный ответ.
Поддержка мультимодальности
Особое внимание в RRNCB уделяется мультимодальным возможностям RAG решений. Оценивается процент корректных ответов на комплексные запросы, включающие работу с текстом и таблицами одновременно. Это критически важно для корпоративных сценариев, где документы часто содержат структурированные данные наряду с текстовыми описаниями.
Мультимодальные задания включают:
- Извлечение данных из таблиц с последующим текстовым анализом
- Сопоставление информации между различными разделами документов
- Интерпретация числовых показателей в контексте текстовых требований
Практическая ценность
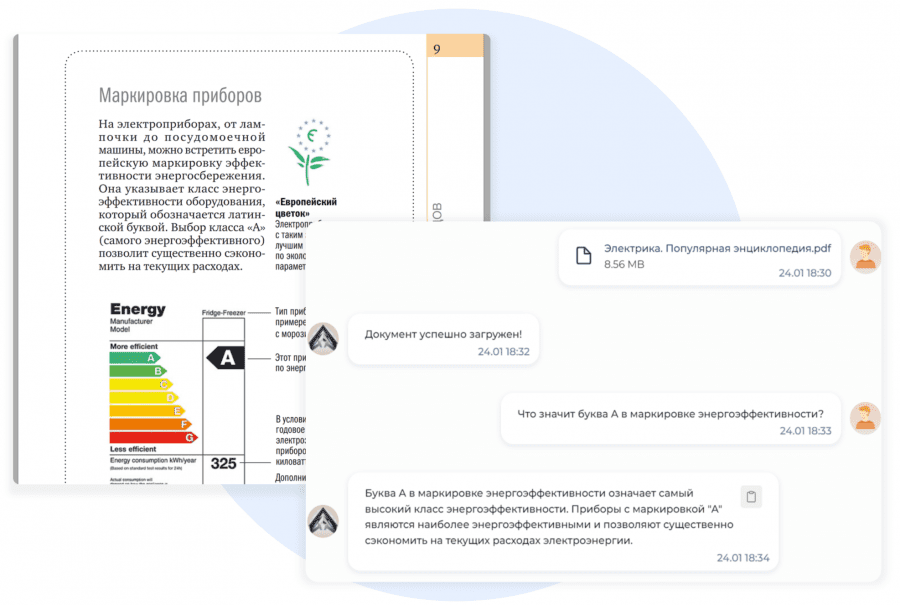
RRNCB призван упростить выбор RAG решения коммерческим и производственным компаниям. Независимый лидерборд предоставляет объективную оценку современных RAG решений, позволяя принимать обоснованные решения о внедрении генеративного ИИ в бизнес на основе количественных метрик.
Участие в бенчмарке требует работы продукта через API с отправкой вопросов, получением ответов и загрузкой документов. Это подход «черного ящика», который оценивает готовые решения в реальных условиях использования.
Экспертный совет бенчмарка включает лидеров IT индустрии и специалистов из ведущих российских технологических компаний и исследовательских центров, что обеспечивает профессиональный подход к методологии оценки.
RRNCB выпускается как открытый проект с возможностью участия для любых разработчиков RAG решений. Создание отраслевого бенчмарка позволит продолжить тренд на возрастающую потребность оценки потребительских характеристик GenAI и выйти на уровень мировых бенчмарков типа MERA, SuperGLUE, DRAGON, LMArena, RAGBench.







