ScaNN — это библиотека для поиска близких векторов. Разработкой библиотеки занимались исследователи Google AI.
Описание проблемы
Поиск совпадающих строк в базе данных обычно осуществляется с помощью скриптовых языков, как SQL. Однако когда задача — это найти объекты по более абстрактному запросу, поиск по количеству совпадающих слов в тексте не работает. Например, задача — вытащить все объекты, в которых есть поэма о Гражданской войне.
Современные ML-модели трансформируют входные данные в эмбеддинги. Наиболее близкие семантически входные данные располагаются в пространстве эмбеддингов ближе друг к другу. Поиск близких эмбеддингов в пространстве — это способ решить задачу абстрактных запросов к данным.
Что внутри ScaNN
Идея, которую предлагают исследователи, заключается в следующем:
- Получаем эмбеддинг целевого запроса;
- В пространстве ищем наиболее близкие к целевому запросу эмбеддинги объектов;
- Наиболее близкие эмбеддинги — это и есть результат запроса
Однако из-за того, что количество эмбеддингов может быть большим, задача все еще остается вычислительно затратной. Чтобы снизить вычислительную сложность поиска по эмбеддингам, исследователи разработали ScaNN.
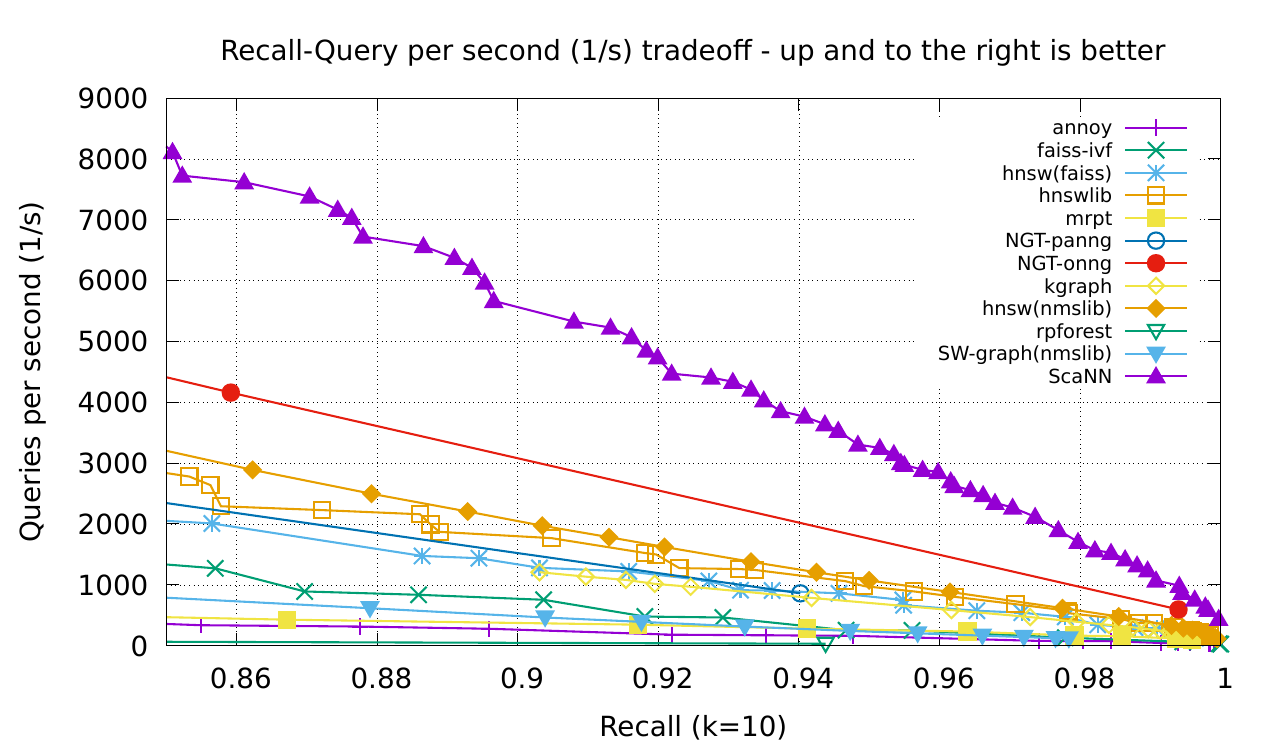
ScaNN использует метод квантизации эмбеддингов, который позволяет сократить их размер. При этом семантическая информация об объектах сохраняется. По результатам экспериментов, использование предложенного метода сжатия позволяет меньше всего потерять в точности предсказанных соседей. ScaNN обходит предыдущие библиотеки для поиска похожих векторов.
