Исследователи из Google AI предлагают метод для широкомасштабного представления графов в виде векторов.
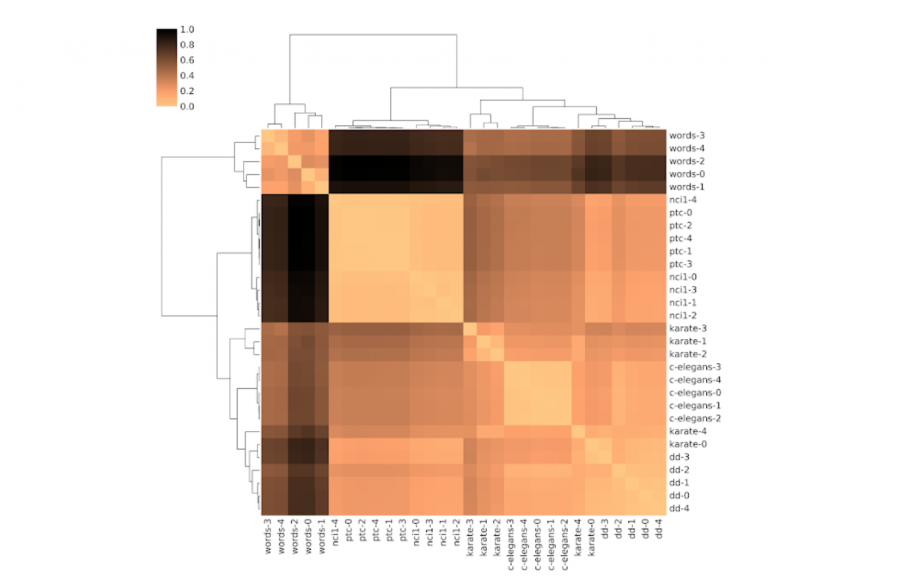
Понимание различий и схожестей между комплексными датасетами — это один из актуальных вопросов в работе с данными. Одним из способов формализовать задачу является представить каждый датасет в виде графа, который описывает взаимосвязи между объектами датасета. Чтобы искать схожие и отличные датасеты, необходимо выучить векторное пространство для представления графов.
Обучение без учителя для поиска схожих графов
DDGK — это метод, который позволяет выучивать представления для близости графов без дополнительных знаний о домене или разметки. Метод кодирует графы в виде векторов и соотношения близости между этими векторами. Модель совместно выучивает представления узлов, графа и соотнесение между графами с помощью механизма внимания.
Проблема DDGK заключается в том, что он неэффективен для работы с большими графами или большими наборами графов. Чтобы масштабировать DDGK на большие графы, исследователи предложили SLaQ. SLaQ аппроксимирует набор дескрипторов графа, а не вычисляет их напрямую. Это позволяет оптимизировать количество вычислительных ресурсов, которые требуются на обработку графа.
Применение SLaQ в реальных задачах
Исследователи протестировали SLaQ на задаче мониторинга аномальных изменений в структуре графа Википедии. Метод позволяет отличить информативные изменения в структуре графа страницы от неинформативных. Примером неинформативного изменения является массовое переименование страниц.
