TAPAS — это инструмент для поиска ответа на вопрос в табличных данных. В основе системы лежит архитектура BERT. Модель кодирует вопрос на естественном языке совместно с структурой табличных данных. На выходе система отдает наиболее релевантные данные из таблицы.
Проблема текущих подходов
Большинство информации хранится в формате таблиц, которые можно найти в сети или в базах данных и документах. На данный момент основным способом поиска по табличным данным является ручной поиск. Исследователи предлагают метод для написания запросов на естественном языке к таблицам.
Предыдущие подходы применяют традиционный семантический парсинг для решения этой задачи. В таком случае вопрос на естественном языке переводится в запрос на SQL-подобном языке. Запрос исполняется, и пользователь получает ответ с наиболее релевантными данными из таблицы. Недостатком такого подхода является необходимость генерировать синтаксически и семантически валидные запросы. Кроме того, такая система не масштабируется на новые типы вопросов.
Как обрабатывается вопрос
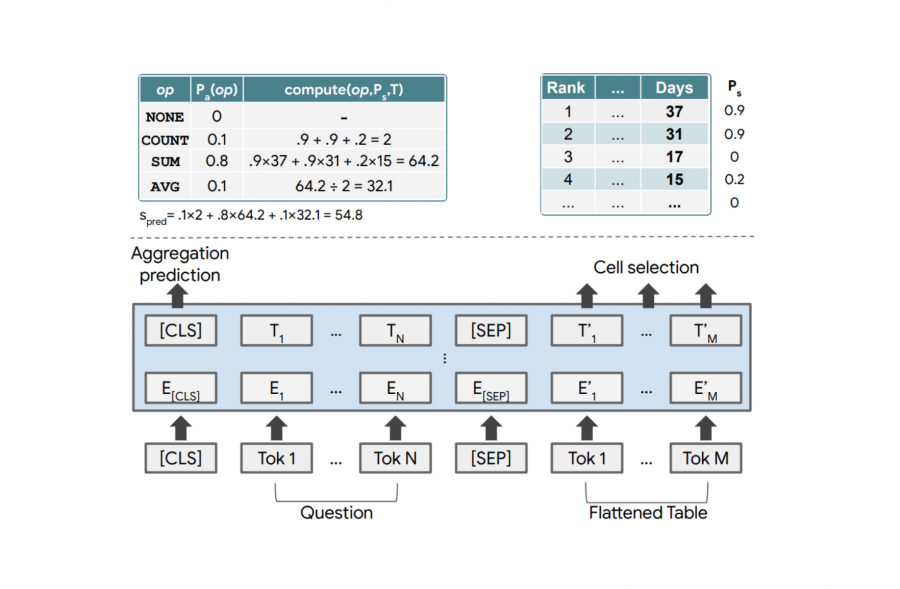
Чтобы обработать вопрос “Average time as champion for top 2 wrestlers?”, предложенная модель совместно кодирует вопрос и структуру таблицы построчно. Для кодирования используется архитектура BERT. Исследователи расширили стандартную модель специальным эмбеддингом, который кодирует структуру таблицы.
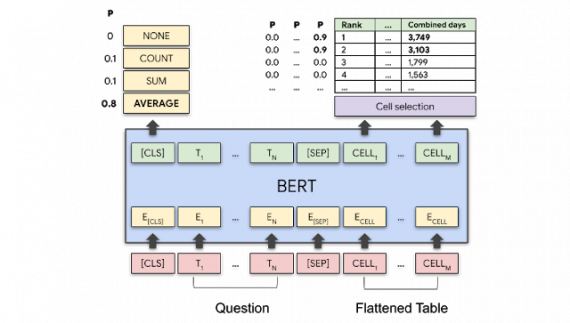
Модель на выходе отдает:
- Для каждой ячейке в таблице — вероятность того, что эта ячейка является частью ответа;
- Операция, которая применялась при формировании итогового ответа
Тестирование модели
Исследователи протестировали модель на трех датасетах: SQA, WikiTableQuestions (WTQ) и WikiSQL, — и сравнили с тремя state-of-the-art моделями. Предложенная модель обходит предыдущие подхода на более чем 12 пунктов на датасете SQA.
