
Супер-разрешение — это результат восстановления изображения с высоким разрешением (HR) из данного изображения с низким разрешением (LR). В этой статье приведены основные подходы для решения задачи генерации супер-разрешения изображения с учителем. Изображение может иметь «более низкое разрешение» из-за меньшего пространственного разрешения (то есть размера) или из-за ухудшения качества (такого как размытие). Мы можем связать изображения HR и LR с помощью следующего уравнения: LR = degradation(HR).
Читайте также: Нейросети для улучшения качества фото: обзор онлайн сервисов
Очевидно, что при применении функции ухудшения качества мы получаем изображение LR из изображения HR. Но можем ли мы сделать обратное? В идеальном случае да! Если мы знаем точную функцию деградации, применяя ее инверсию к изображению LR, мы можем восстановить изображение HR.
Но в этом и заключается проблема. Обычно мы не знаем эту функцию заранее. Непосредственная оценка обратной функции деградации является некорректной задачей. Несмотря на это, методы глубокого обучения доказали свою эффективность для супер-разрешения. Используя изображение HR в качестве цели и изображение LR в качестве входных данных, мы можем рассматривать это как задачу обучения с учителем.
Эта статья в основном посвящена ознакомлению с супер-разрешением с использованием глубокого обучения с использованием методов обучения с учителем. Также в ней обговариваются некоторые важные функции потерь и метрики. Большая часть контента взята из этого обзора методов, на который вы можете ссылаться.
Подготовка данных
Одним из простых способов получения данных LR является ухудшение данных HR. Это часто делается с помощью размытия или добавления шума. Изображения с более низким пространственным разрешением также можно масштабировать с помощью классического метода повышения дискретизации, такого как билинейная или бикубическая интерполяция. Особенности JPEG и аномалии квантования также могут быть использованы для ухудшения изображения.

Важно отметить, что рекомендуется хранить изображение HR в несжатом (или сжатом без потерь) формате. Это должно предотвратить ухудшение качества изображения HR из-за сжатия с потерями, которое может дать низкую производительность.
Типы сверток
Помимо классических 2D-сверток, в сетях можно использовать несколько интересных вариантов для улучшения результатов. Развернутые (злокачественные) свертки могут обеспечить более широкое поле зрения, то есть, использовать информацию, расположенную на большом расстоянии. Такие приемы, как пропуск соединений, пространственный пирамидальный пуллинг и полносвязные блоки объединеняют признаки как низкого, так и высокого уровня для повышения производительности.
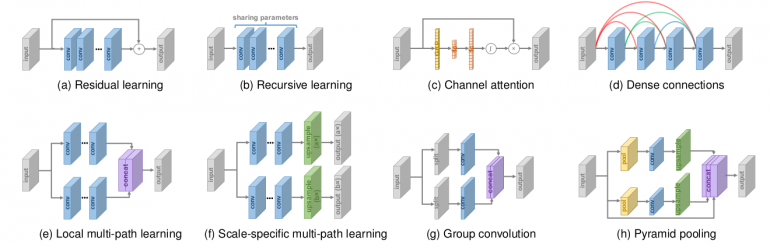
На приведенном выше изображении приводится ряд стратегий проектирования сетей. Вы можете обратиться к этой статье для получения дополнительной информации. Для ознакомления с различными типами сверток, обычно используемых в глубоком обучении, вы можете обратиться к этому блогу.
Методы супер-разрешения
Предварительное увеличение разрешения (Pre-Upsampling)
В этой группе методов изображения с низким разрешением сначала интерполируются для получения «грубых» изображений с большим разрешением. Теперь CNN используются для обучения end-to-end отображения от интерполированных изображений с низким качеством до изображений с высоким качеством. Идея этой группы методов состоит в том, что может быть проще сначала увеличить разрешение изображений, используя традиционные методы (такие как билинейная интерполяция), а затем сделать резул результирующий результат, чем изучить прямое отображение из низкоразмерного пространства в многомерное пространство.
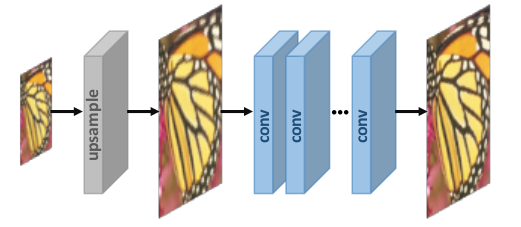
Вы можете обратиться к странице 5 этого документа для просмотра информации о моделях, использующих эту технику. Преимущество состоит в том, что, поскольку Upsampling обрабатывается традиционными методами, CNN нужно только научиться уточнять грубое изображение, что проще. Более того, поскольку здесь мы не используем транспонированные свертки, есть возможность не допустить «артефактов шахматной доски«. Однако недостаток этой группы методов заключается в возможном усилении шумов и размытия изображения из-за предварительного повышения разрешения.
Пост-увеличение разрешения (Post-Upsampling)
В этом случае на CNN подаются оригинальные изображения с низким разрешением. Повышение разрешения выполняется на последнем обучаемом слое.
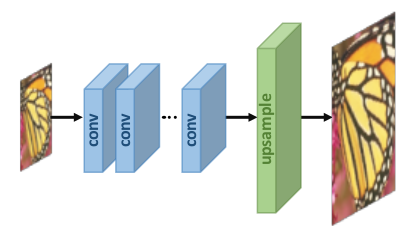
Преимущество этого метода состоит в том, что извлечение признаков выполняется в пространстве меньшего размера (перед повышением разрешения), и, следовательно, вычислительная сложность уменьшается. Кроме того, используя обучаемый слой upsampling, модель можно обучать end-to-end.
Прогрессивное увеличение разрешения (Progressive Upsampling)
В группе методов с пост-увеличением разрешения, хотя вычислительная сложность и была снижена, но использовалась только одна свертка с повышением размерности. Это усложняет процесс обучения при больших коэффициентах масштабирования. Для устранения этого недостатка, в таких работах, как сеть Laplacian Pyramid SR (LapSRN) и Progressive SR (ProSR), была принята концепция прогрессивного увеличения разрешения. Модели в этом случае используют каскад CNN для постепенного восстановления изображений с высоким разрешением при меньших коэффициентах масштабирования на каждом этапе.
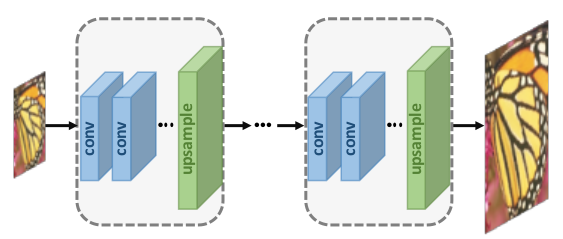
Раскладывая сложную задачу на более простые, трудность в обучении значительно снижается, и можно добиться лучшей производительности. Кроме того, стратегии обучения, такие как обучение по учебному плану, могут быть интегрированы для дальнейшего снижения сложности обучения и повышения итоговой успеваемости.
Итеративное понижение и повышение разрешения
Другой популярной моделью архитектуры является структура песочных часов (или U-Net). В некоторых вариантах, таких как сеть Stacked Hourglass, используется несколько последовательных структур песочных часов, которые эффективно чередуются между процессами повышения и понижения размерности.
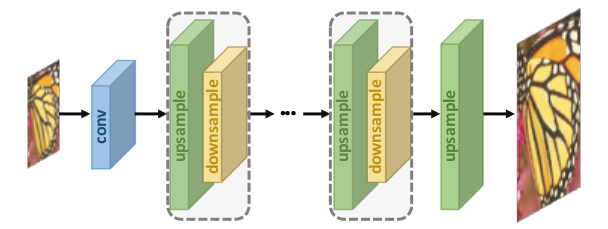
Модели в этой структуре могут лучше определить глубокие отношения между парами изображений LR-HR и, таким образом, обеспечить более качественные результаты реконструкции.
Функции потерь
Функции потерь используются для измерения разницы между сгенерированным изображением высокого разрешения и настоящим изображением высокого разрешения. Эта разница (ошибка) затем используется для оптимизации модели обучения с учителем. Существует несколько классов функций потерь, каждый из которых оштрафовывает свой аспект генерируемого изображения.
Часто более одной функции потерь используется путем взвешивания и суммирования ошибок, полученных от каждой функции потерь в отдельности. Это позволяет модели сосредоточиться на аспектах, одновременно вносимых множественными функциями потерь.
total_loss = weight_1 * loss_1 + weight_ 2 * loss_2 + weight_3 * loss_3
В этом разделе мы рассмотрим некоторые популярные классы функций потерь, используемые для обучения моделей.
Пиксельная ошибка (Pixel Loss)
Пиксельная ошибка — это самый простой класс функций потерь, где каждый пиксель в сгенерированном изображении напрямую сравнивается с каждым пикселем в настоящем изображении. Используются популярные функции потерь, такие как потери L1 или L2, или расширенные варианты, такие как потери Smooth L1.
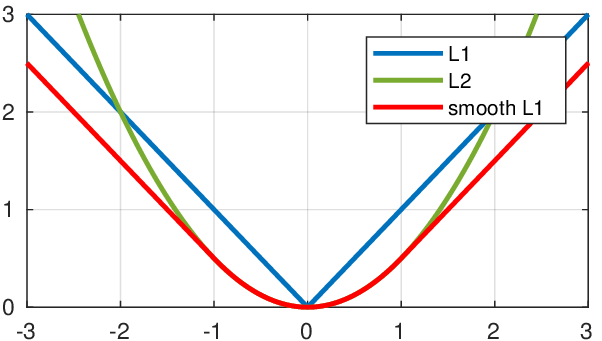
Метрика PSNR (обсуждаемая ниже) сильно коррелирует с разностью пикселей, и, следовательно, минимизация потери пикселей напрямую максимизирует значение метрики PSNR (что указывает на хорошую производительность). Тем не менее, пиксельная ошибка не учитывает качество изображения, и модель часто выдает неудовлетворительные результаты.
Ошибка содержимого (Content Loss)
Эта ошибка оценивает качество изображения на основе его воспринимаемого качества. Интересный способ сделать это — сравнить характеристики высокого уровня сгенерированного изображения и настоящего изображения. Мы можем получить эти функции высокого уровня, передав оба этих изображения через предварительно обученную сеть классификации изображений (например, VGG-Net или ResNet).
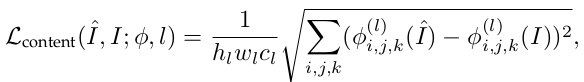
Вышеупомянутое уравнение вычисляет потерю контента между настоящим и сгенерированным изображением, учитывая предварительно обученную сеть (Φ) и слой ( l ) этой предварительно обученной сети, на котором вычисляются потери. Эта потеря способствует тому, что сгенерированное изображение воспринимается как настоящее изображение. По этой причине эта ошибка также известна как ошибка восприятия (perceptual loss).
Ошибка текстуры
Чтобы позволить сгенерированному изображению иметь тот же стиль (текстуру, цвет, контраст и т.д.), что и у настоящего изображения, используется вычисление ошибки текстуры (или ошибка реконструкции стиля). Текстура изображения, как описано Gatys et. al, определяется как корреляция между различными характерными каналами. Каналы объектов обычно получают из карт признаков, извлеченных с использованием предварительно обученной сети классификации изображений (Φ).
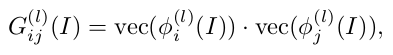
Корреляция между картами признаков представлена матрицей Грама (G), которая является внутренним произведением между векторизованными картами объектов i и j на слое l (показано выше). Как только матрица Грамма рассчитана для обоих изображений, вычисляется ошибка текстуры:
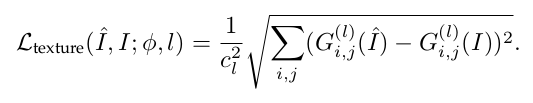
Используя эту ошибку, модель мотивируется создавать реалистичные текстуры и визуально более удовлетворительные результаты.
Полная вариационная ошибка
Ошибка суммарного отклонения (TV) используется для подавления шума в сгенерированных изображениях. Он берет сумму абсолютных разностей между соседними пикселями и измеряет, сколько шума на изображении. Для сгенерированного изображения ошибки TV рассчитываются, как показано ниже:
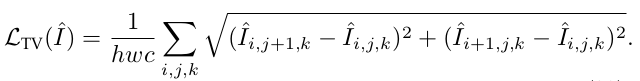
Здесь i, j, k перебирает высоту, ширину и каналы соответственно.
Состязательная ошибка
Генеративные состязательные сети (GAN) все чаще используются для для задач, основанных на изображениях, включая супер-разрешение. GAN обычно состоят из системы двух нейронных сетей — Генератора и Дискриминатора, которые противостоят друг другу.
Учитывая набор целевых образцов, Генератор пытается создать образцы, которые могут обмануть Дискриминатора, заставив его поверить, что они реальны. Дискриминатор пытается отличить реальные (целевые) выборки от поддельных (сгенерированных) выборок. Используя этот итеративный подход к обучению, мы в конечном итоге получим Генератор, который действительно хорош в создании образцов, подобных целевым образцам. На следующем рисунке показана структура типичного GAN.
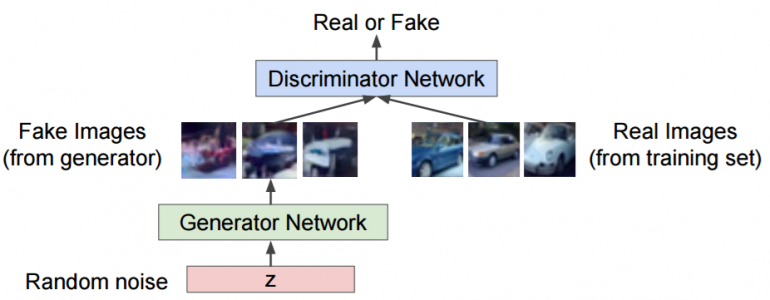
Усовершенствования базовой архитектуры GAN были введены для повышения производительности. Вы можете посмотреть этот блог для более подробной информации о достижениях в GAN.
Как правило, модели, обученные с состязательной ошибкой, имеют лучшее качество восприятия, даже если они могут проиграть по метрике PSNR по сравнению с теми, которые обучены с ошибкой пикселей. Недостатком является то, что процесс обучения GAN немного сложен и нестабилен. Тем не менее, методы стабилизации обучения GAN активно разрабатываются.
Метрики
Один большой вопрос заключается в том, как мы можем количественно оценить производительность нашей модели. Ряд методов оценки качества изображения (IQA) (или метрики) используются для одного и того же. Эти метрики можно в целом классифицировать на две категории - субъективные метрики и объективные метрики.
Субъективные метрики основаны на оценке восприятия человеком-наблюдателем, тогда как объективные метрики основаны на вычислительных моделях, которые пытаются оценить качество изображения. Субъективные метрики часто являются более «точными для восприятия», однако некоторые из этих метрик неудобны, трудоемки или дороги для вычисления. Другая проблема заключается в том, что эти две категории метрик могут не соответствовать друг другу. Следовательно, исследователи часто анализируют результаты, используя метрики из обеих категорий.
В этом разделе мы кратко рассмотрим несколько широко используемых метрик для оценки производительности нашей модели с супер-разрешением.
PSNR
Пиковое отношение сигнал/шум (PSNR) — это обычно используемая объективная метрика для измерения качества восстановления преобразования с потерями. PSNR обратно пропорционально логарифму средней квадратичной ошибки (MSE) между настоящим и сгенерированным изображением.
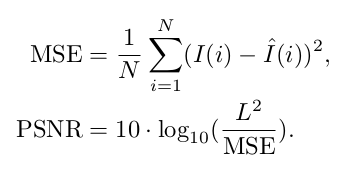
В приведенной выше формуле L — максимально возможное значение пикселя (для 8-битных изображений RGB — 255). Неудивительно, что, поскольку PSNR заботится только о разнице между значениями пикселей, он не так хорошо отражает воспринимаемое качество.
SSIM
Структурное сходство (SSIM) — это субъективная метрика, используемая для измерения структурного сходства между изображениями на основе трех относительно независимых сравнений, а именно: яркости, контрастности и структуры. Абстрактно, формула SSIM может быть показана как взвешенное произведение яркости, контраста и структуры, вычисленных независимо.
![]()
В приведенной выше формуле альфа, бета и гамма являются весами функций сравнения яркости, контраста и структуры соответственно. Обычно используемое представление формулы SSIM показано ниже:
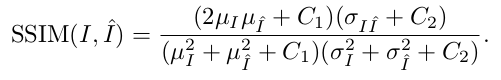
В приведенной выше формуле μ(I) представляет среднее значение конкретного изображения, σ(I) представляет стандартное отклонение конкретного изображения, σ(I, I’) представляет ковариацию между двумя изображениями и C1, C2 задают константы, чтобы избежать нестабильности. Для краткости, значение терминов и точный вывод не объяснены в этой статье, но заинтересованный читатель может ознакомиться с ними в разделе 2.3.2 в этой статье.
Из-за возможного неравномерного распределения статистических характеристик или искажений изображения локальная оценка качества изображения более надежна, чем его оценка в глобальном масштабе. Среднее значение SSIM (MSSIM), которое разбивает изображение на несколько окон и усредняет значение SSIM, полученное в каждом окне, является одним из таких методов оценки качества на локальном уровне.
В любом случае, поскольку SSIM оценивает качество реконструкции с точки зрения зрительной системы человека, эта метрика лучше соответствует требованиям оценки восприятия.
Другие результаты IQA
Без объяснения, некоторые другие метрики оценки качества изображения перечислены ниже. Заинтересованный читатель может обратиться к этой статье для более подробной информации.
- Средняя оценка мнений (MOS);
- Оценка на основе задач;
- Критерий достоверности информации (IFC);
- Визуальная достоверность информации (VIF).
Заключение
В этой статье были рассмотрены некоторые вводные материалы и процедуры для обучения моделей глубокого обучения для задачи супер-разрешения. На самом деле, благодаря современным исследованиям, существуют более продвинутые методики, которые могут дать лучшую производительность. Кроме того, исследование таких направлений, как супер-разрешение без учителя, лучшие методы нормализации и лучшие репрезентативные метрики, могут значительно расширить эту область. Заинтересованным читателям предлагается экспериментировать с их инновационными идеями, участвуя в таких задачах, как PIRM Challenge.






