
Исследователи из компании Xiaohongshu представили DeepEyesV2 — агентную мультимодальную модель на базе Qwen2.5-VL-7B, которая умеет не просто понимать текст и изображения, но и активно использовать внешние инструменты: выполнять код на Python и искать информацию в интернете. В отличие от существующих моделей, работающих либо только с изображениями, либо только с поиском, DeepEyesV2 объединяет оба подхода в единый цикл рассуждений.
Проект полностью открыт. Исследователи опубликовали веса обученной модели на HuggingFace, код обучения под лицензией Apache в GitHub репозитории, а также полностью открыли обучающие датасеты: Cold Start данные и RL датасет. В экспериментах также протестированы модели на базе Qwen2.5-VL-32B, демонстрирующие применимость подхода к более крупным моделям.
Проблема существующих подходов
Современные мультимодальные языковые модели (MLLM) хорошо понимают изображения и текст, но остаются пассивными. Они не могут самостоятельно вызывать инструменты для работы с изображениями или получения актуальной информации из интернета.
Например, если попросить модель определить вид цветка на фотографии, простая модель попытается ответить на основе своих знаний и часто ошибется. DeepEyes (предыдущая версия) научилась обрезать нужную область для детального анализа, но не могла проверить ответ через поиск. MMSearch-R1 умеет искать в интернете, но плохо работает с мелкими деталями. А DeepEyesV2 сначала обрежет область с цветком, потом найдет похожие изображения через поиск, затем проверит информацию текстовым запросом — и только после этого даст точный ответ.
Как устроена DeepEyesV2
DeepEyesV2 работает циклически: модель сама решает, когда и какие инструменты вызывать, получает результаты и интегрирует их в процесс рассуждения.
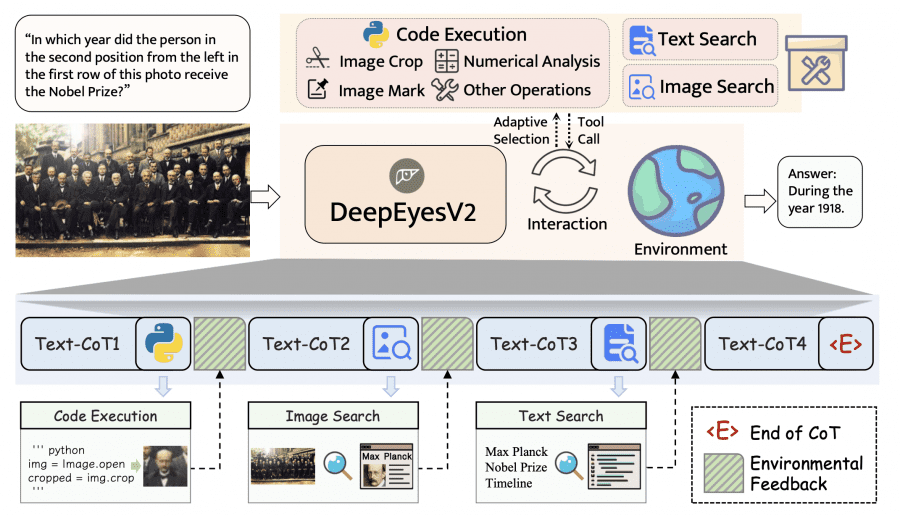
Доступные инструменты включают выполнение Python-кода для работы с изображениями и данными (обрезка, численный анализ, разметка), поиск по изображению через SerpAPI (топ-5 визуально похожих результатов) и текстовый поиск (топ-5 релевантных веб-страниц).
Почему прямое обучение с подкреплением не работает
Исследователи сначала попробовали обучить модель Qwen2.5-VL напрямую через обучение с подкреплением (RL). Результат оказался неожиданным: на ранних этапах модель генерировала код с ошибками, затем постепенно отказывалась от инструментов и выдавала только короткие рассуждения.
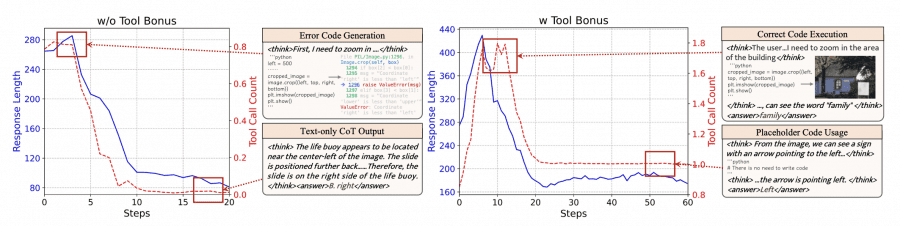
После добавления бонуса за использование инструментов модель начала генерировать один блок неисполняемых комментариев на каждый запрос — классический пример reward hacking. Этот эксперимент показал: существующие модели не могут надежно научиться использовать сложные инструменты через прямое RL. Им нужна предварительная подготовка — холодный старт.
Двухэтапное обучение
Этап 1: Холодный старт
Исследователи собрали датасет, охватывающий задачи восприятия, рассуждения и поиска. Датасет прошел строгую фильтрацию: оставили только вопросы, с которыми базовая модель справляется максимум в 2 случаях из 8 попыток, и проверили пользу инструментов.
Данные разделили на два подмножества. Примеры, решенные с инструментами, отложили для RL. Более сложные примеры использовали для холодного старта, сгенерировав для них подробные траектории с помощью продвинутых моделей (Gemini 2.5 Pro, GPT-4o, Claude Sonnet 4). После supervised fine-tuning модель приобрела базовые паттерны использования инструментов.
Этап 2: Обучение с подкреплением
После холодного старта применили RL для дальнейшего улучшения. Функция награды включала награду за точность и штраф за нарушение формата. Важно, что не использовали сложные техники — только две простые метрики.
Согласно документации DeepEyesV2, для обучения требуются значительные вычислительные ресурсы.
Минимальные требования для 7B версии:
- Минимум 32 GPU (4 ноды по 8 GPU каждая);
- Минимум 1200 GB оперативной памяти CPU на каждую ноду;
Причина высоких требований к RAM: изображения высокого разрешения потребляют большой объем памяти.
Для 32B версии:
- Минимум 64 GPU (8 нод по 8 GPU);
- Те же требования по RAM (1200 GB на ноду).
RealX-Bench: новый бенчмарк
Существующие бенчмарки оценивают модели по отдельным способностям, но в реальных задачах они должны работать совместно. Исследователи создали RealX-Bench — бенчмарк для оценки координированной работы восприятия, поиска и рассуждения.
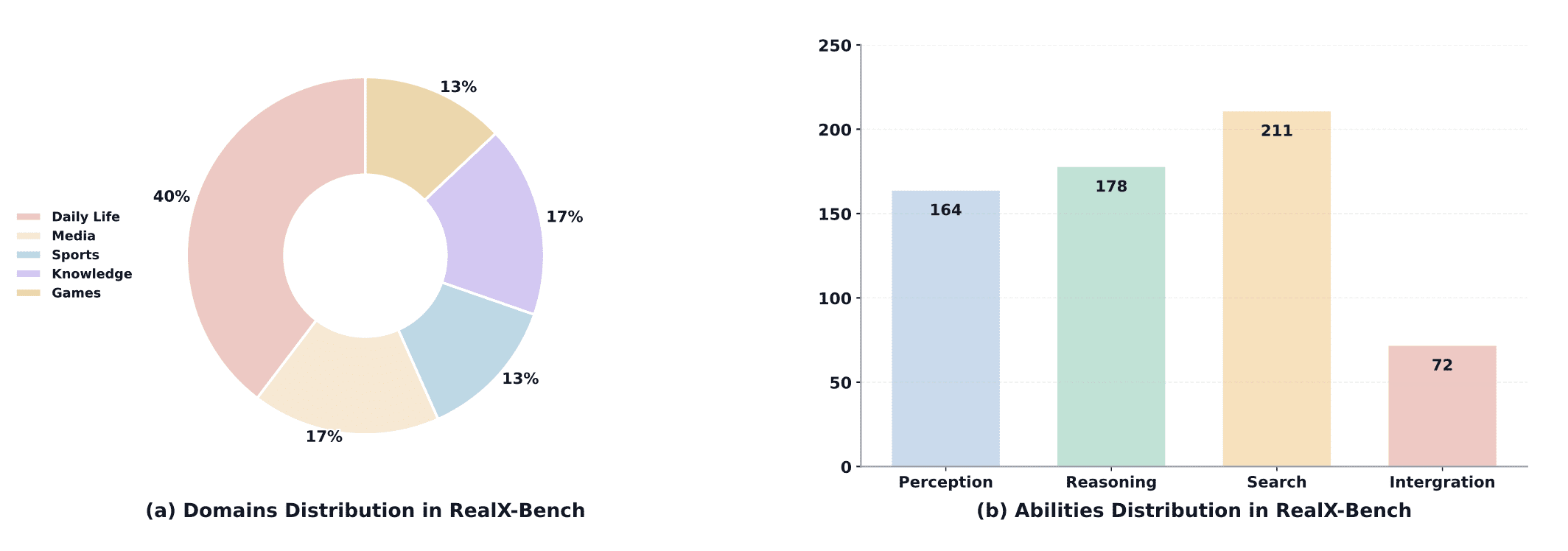
RealX-Bench содержит 300 пар вопрос-ответ из пяти реальных доменов. По уровню сложности: 164 вопроса требуют восприятия, 178 — рассуждения, 211 — поиска. 72 вопроса (24%) одновременно сложны во всех трех аспектах. Даже лучшая модель (Gemini 2.5 Pro) достигает только 46.0% точности, что далеко от человеческого уровня (70.0%).
Результаты экспериментов
DeepEyesV2 показала впечатляющие результаты на трех категориях бенчмарков.
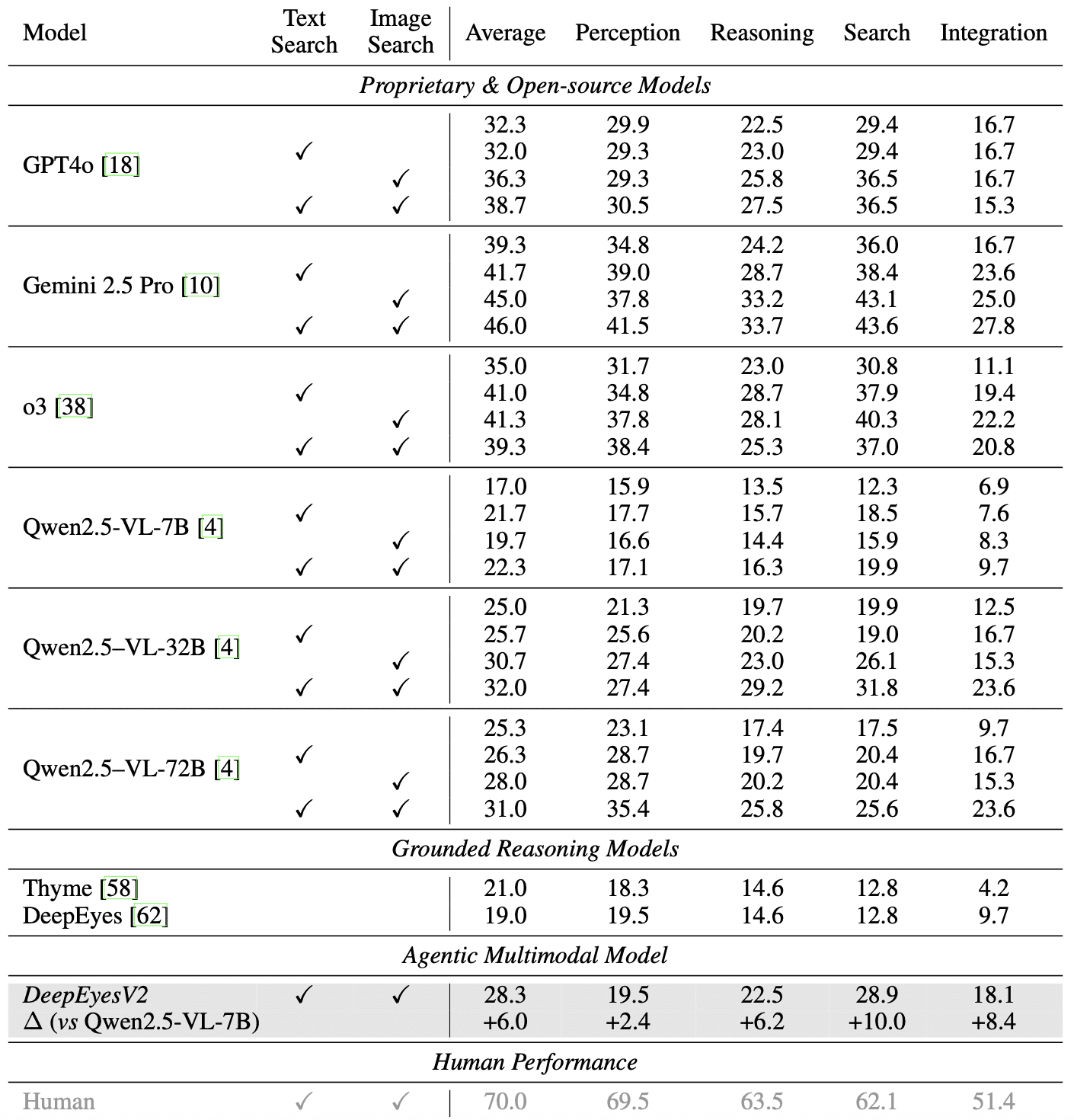
RealX-Bench: 28.3% средней точности (+6.0 п.п. выше базовой модели). На подмножестве интеграции всех трех способностей: 18.1% против 6.9% (+8.4 п.п.):
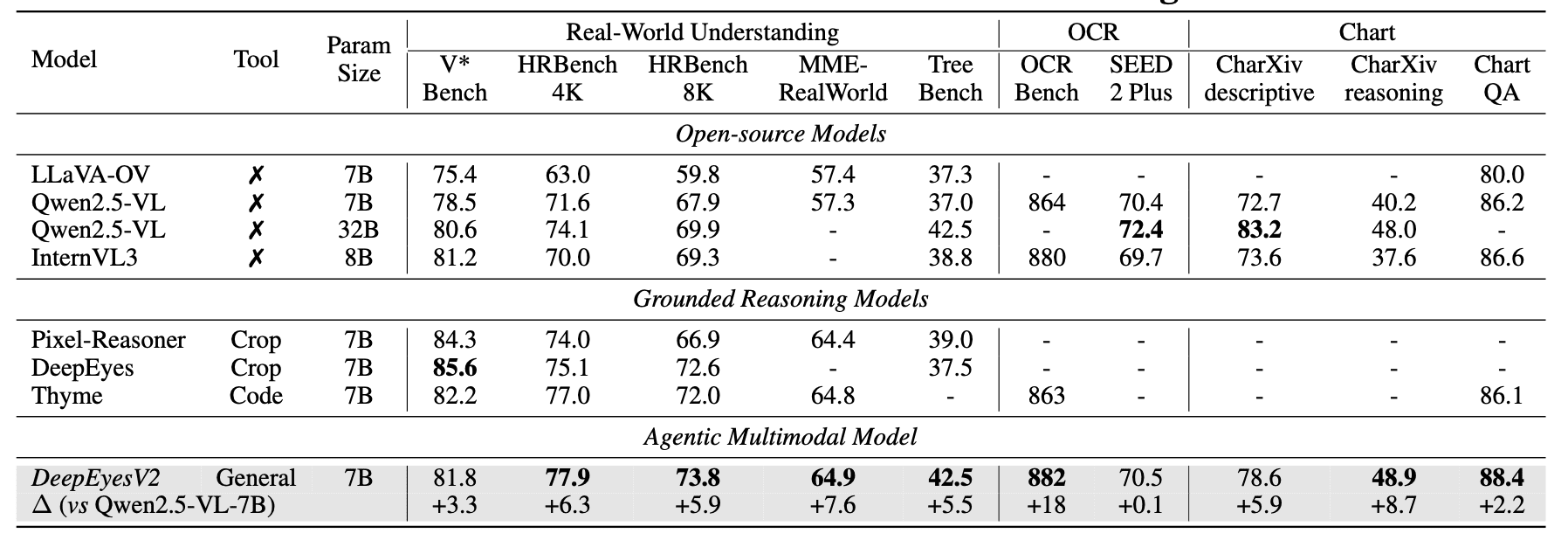
Понимание реального мира. Улучшения от +0.1 до +8.7 процентных пунктов на бенчмарках V*Bench, HRBench, MME-RealWorld и других. На некоторых бенчмарках DeepEyesV2 (7B) превосходит даже Qwen2.5-VL-32B:
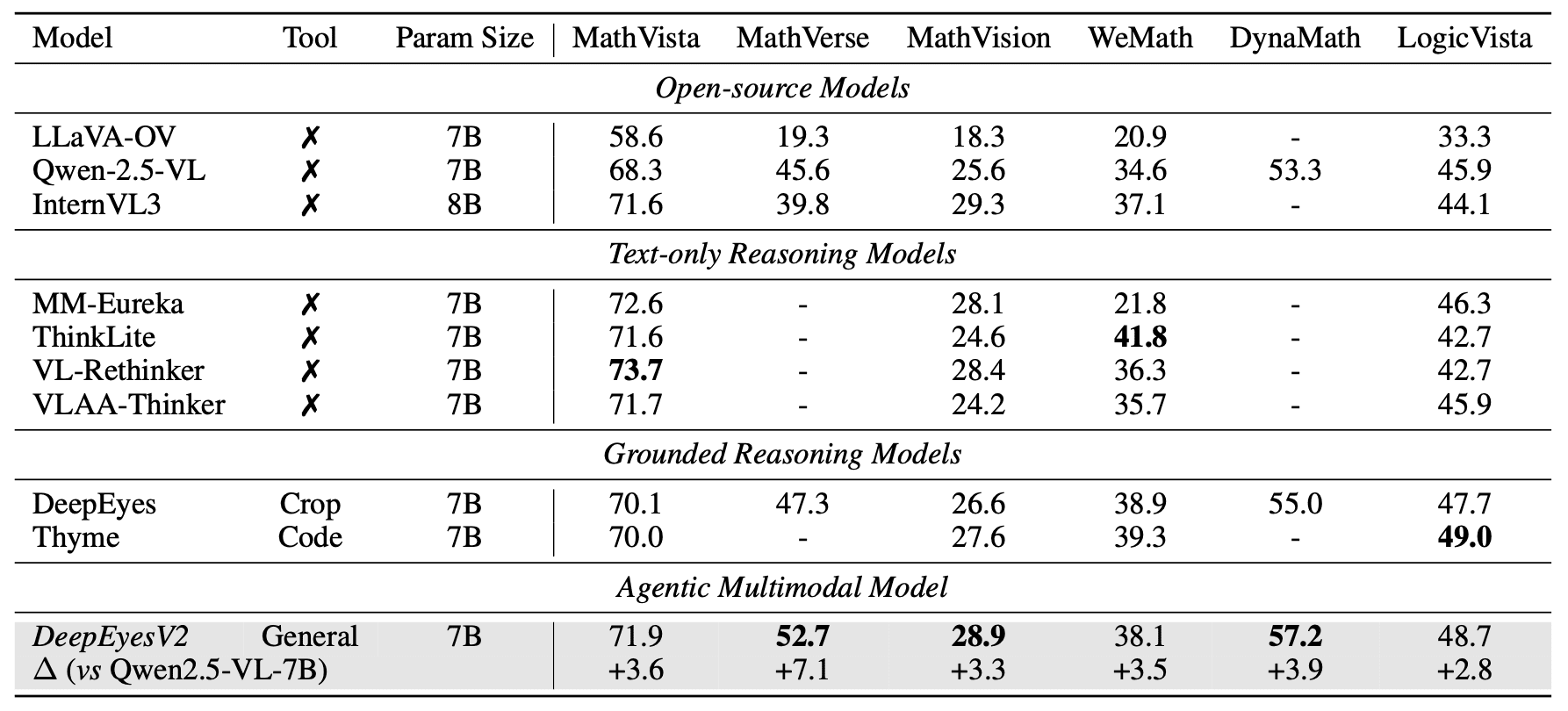
Математическое рассуждение. На MathVerse прирост +7.1 п.п. (до 52.7%), превосходя как общие модели, так и специализированные для рассуждений:
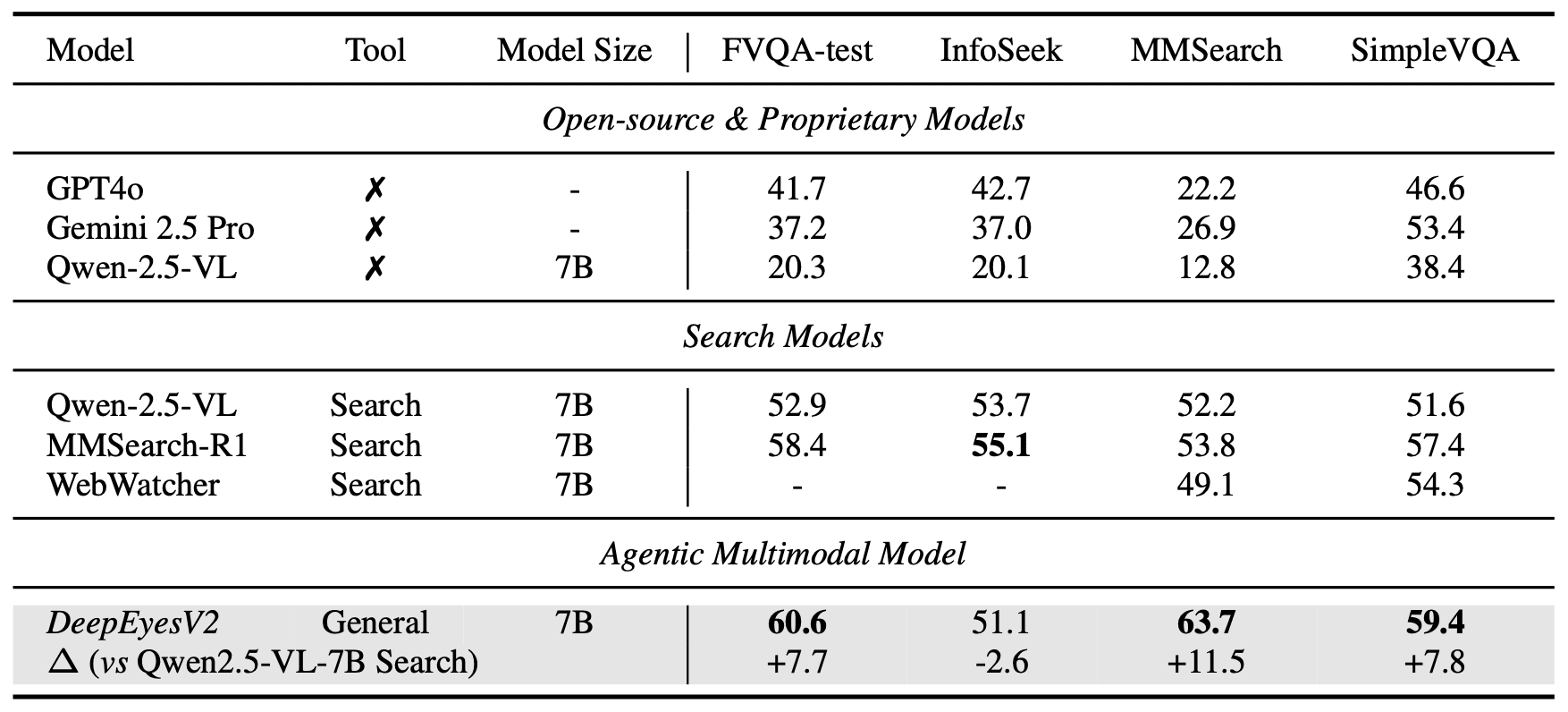
Поиск информации. На MMSearch 63.7% (+11.5 п.п.), значительно опережая специализированную MMSearch-R1 (53.8%):
Анализ поведения модели
DeepEyesV2 демонстрирует четкие адаптивные паттерны. В задачах на восприятие использует обрезку изображений, в математических задачах — вычисления, в поисковых — инструменты поиска. После RL модель начинает интегрировать разные типы инструментов, например, комбинирует обрезку с поиском.
До RL модель чрезмерно полагалась на инструменты. После RL частота вызовов снизилась, но модель научилась адаптивному рассуждению: решает простые задачи напрямую, но использует инструменты когда это полезно.
Анализ данных показал, что разнообразие данных критически важно: комбинирование данных восприятия, рассуждения и длинных цепочек рассуждений дает лучшие результаты.
Главный вывод исследования: несмотря на отличные результаты на академических тестах, до уровня реальной работы агентным моделям еще далеко. RealX-Bench дает конкретные метрики для отслеживания прогресса. Датасет будут расширять, а методологию адаптировать под улучшающиеся модели.





