Модель Vision Transformer без слоёв внимания показала высокие результаты на ImageNet. Это показывает, что механизм внимания не является основной причиной эффективности архитектуры Vision Transformer, вопреки мнению сообщества.
Зачем это нужно
Полезность современных ИИ-архитектур в первую очередь доказывается на практике, а её теоретическое обоснование помогает улучшать существующие модели и разрабатывать новые. Следовательно, очень важно понимать ключевые причины эффективности каждой архитектуры.
На данный момент state-of-the-art в компьютерном зрении является архитектура Vision Transformer (ViT). Высокие показатели ViT в компьютерном зрении часто приписывают дизайну слоёв multi-head attention (перев.: многоголовое внимание). В последнее время значительный объем работы был направлен на повышение их действенности. Однако до сих пор остаётся неясным, насколько важен вклад слоёв внимания. Именно это решил выяснить исследователь Оксфордского Университета.
Как это работает
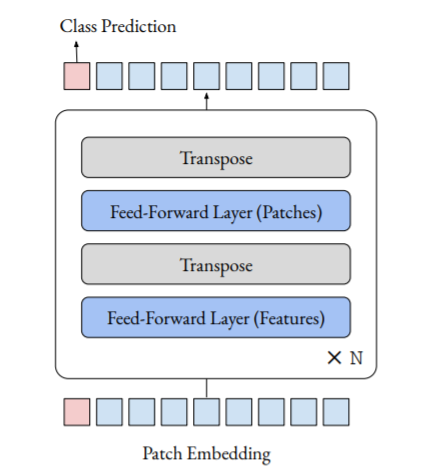
Классическая архитектура ViT разделяет изображение на последовательность фрагментов (патчей), а затем применяет к этой последовательности серию блоков Transformer. Каждый блок Transformer состоит из двух слоёв:
- multi-head attention layer — слой внимания;
- feed-forward layer — слой с прямой связью, применяемый вдоль измерения признаков (простейший односвязный слой).
Исследователь убрал из ViT слои внимания, заменив их слоями с прямой связью вдоль измерения патчей. Получилась последовательность простейших слоёв, разделённых операцией транспонирования.
Результаты
Автор протестировал несколько современных вариаций архитектуры ViT на популярном датасете ImageNet для классифиакции изображений, заменив слои внимания. Модели без внимания работали хуже, но для вариации DeiT удалось достичь поразительно высокой точности (74.9% top-1 accuracy). Для сравнения, точность классических ViT и DeiT составляет 77.9% и 79.9% соответственно. Результаты показывают, что высокая производительность ViT больше связана с разделением на патчи и процедурой обучения, чем с конструкцией слоя внимания. Подобные работы помогают отрасли развиваться, корректируя фокус иследовательского сообщества.
Подробнее об исследовании можно прочитать в статье на arXiv.
Код с предобученными моделями также доступен в репозитории Github.



